Dotyczy wersji 2020.1.x; autor: Dawid Golonka
Wprowadzenie
Niektóre procesy obsługiwane przez system WEBCON BPS, wymagają do swojego działania danych wsadowych. Dane te mogą pochodzić z zewnętrznych źródeł, takich jak bazy danych SQL czy listy SharePoint. W systemie można też tworzyć wewnętrzne źródła, takie jak listy wartości, czy odwołania do danych zawartych w obiegach BPS. Mówiąc o wewnętrznych źródłach nie można pominąć jednej z nowszych funkcjonalności WEBCON BPS jaką są procesy słownikowe, czyli takie, które służą jedynie przechowywaniu informacji.
Ten artykuł ma na celu ułatwienie użytkownikowi wyboru, kiedy do przechowywania danych powinien skorzystać z dedykowanego procesu słownikowego, a kiedy lepszym wyborem będzie stworzenie standardowego procesu według własnego pomysłu.
Proces słownikowy
Funkcjonalność procesów słownikowych została wprowadzona w wersji WEBCON BPS 2020. Wraz z każdym procesem słownikowym tworzone jest predefiniowane źródło danych, zwracające wszystkie elementy słownika. Struktura źródła zawiera wszystkie atrybuty zdefiniowane w procesie i jest aktualizowana po każdej zmianie konfiguracji procesu słownikowego. Proces ten tworzony jest przy użyciu kreatora, jego budowa jest ujednolicona oraz posiada możliwość migracji danych między środowiskami.
Więcej o słownikach i sposobie ich tworzenia: https://kb.webcon.pl/procesy-slownikowe/
Proces standardowy
W przeciwieństwie do dedykowanego procesu słownikowego, proces standardowy tworzony jest ręcznie (bez użycia kreatora) i wymaga samodzielnej konfiguracji. Wynikiem czego tak stworzony słownik nie jest ustandaryzowany. Rzeczą, która odróżnia proces standardowy od dedykowanego jest brak możliwości importu i eksportu danych między środowiskami.
Różnice w działaniu obu rozwiązań
Poniższa tabela przedstawia różnice w poszczególnych cechach oby rodzajów procesów do obsługi danych słownikowych:
| Proces słownikowy | Proces standardowy |
| Proces generowany jest automatycznie po wybraniu odpowiedniej opcji w WEBCON BPS Designer Studio | Proces należy utworzyć samodzielnie |
| Automatycznie tworzone jest źródło danych, gdzie przechowywane są dane z atrybutów procesu | Chcący odwołać się do wartości przechowywanych w procesie, należy samodzielnie utworzyć źródło BPS |
| Proces słownikowy zbudowany jest z jednego obiegu z jednym krokiem – nie ma możliwości ingerowania w liczbę kroków i dodawania ścieżek przejścia
|
Tworząc proces samodzielnie sami decydujemy, z jakiej ilości kroków i obiegów ma się składać oraz jakimi ścieżkami będzie można przechodzić między krokami |
| Proces słownikowy nie obsługuje list pozycji, jednak poszczególne obiegi mogą być inicjalizowane przez zawartość pliku Excel, dodawanego z poziomu raportu. Wtedy każdy wiersz danych z arkusza staje się osobnym elementem w obiegu | W standardowym procesie można korzystać z wszystkich rodzajów atrybutów, włącznie z listami pozycji |
| Proces słownikowy może być w szybki i łatwy (niewymagający dodatkowej konfiguracji) sposób uzupełniany i uaktualniany dużą ilością danych, poprzez import danych wsadowych z pliku Excel. Istnieje również możliwość ręcznego dodawania i modyfikacji elementów
|
Proces można uzupełniać ręcznie poprzez formularz, lub skonfigurować na formularzu atrybut typu „lista pozycji” co umożliwia import danych z pliku Excel |
| Brak możliwości dodawania załączników | Istnieje możliwość dodawania załączników |
| Możliwość migracji danych między środowiskami | Brak mechanizmu importu/eksportu danych między środowiskami |
Które rozwiązanie wybrać?
Osoba projektująca obsługę procesów biznesowych, samodzielnie powinna zdecydować, które rozwiązanie jest dla niej bardziej optymalne. Wybierając któryś z wariantów należy zestawić jego cechy z aktualnymi wymaganiami co do tworzonego słownika.
Kiedy lepszy będzie dedykowany proces słownikowy?
- gdy posiadamy plik wsadowy z danymi (Excel, plik tekstowy, który można przerobić na arkusz Excela itp.). Import i eksport danych ze skoroszytu jest funkcją wbudowaną, nie wymagającą w dedykowanym procesie słownikowym dodatkowej konfiguracji. Dodatkowo możliwa jest migracja zawartości słownika między środowiskami – w przeciwieństwie do procesu standardowego;
- gdy dodawanie nowych danych będzie odbywało się na tyle często i będzie ich na tyle dużo, że ręczne wprowadzanie ich do słownika będzie znacznie wolniejsze niż import z pliku Excel, a nie potrzebujemy dodatkowej funkcjonalności, której ten typ procesu nie udostępnia;
- gdy na moment, w którym tworzymy słownik nie przewidujemy, że w przyszłości będziemy chcieli dołożyć do niego dodatkowe mechanizmy (wysyłanie wiadomości, kroki akceptacyjne itp.);
- gdy nie mamy potrzeby składowania danych w słowniku w listach pozycji;
- gdy wiemy, że dane w słowniku teraz i w przyszłości nie będą wymagały dodawania plików załączników.
Kiedy lepszy będzie samodzielnie tworzony proces pełniący funkcję słownika?
- gdy do swojego działania słownik potrzebuje funkcjonalności nie oferowanej przez dedykowany proces słownikowy, tj.:
- dodanie kroków, w których ktoś akceptował będzie dane itp.,
- obsługa różnych ścieżek, którymi dane będą migrowały między krokami,
- dane będą przechowywane w kilku różnych stanach dostępności (np. dane aktywne, nieaktywne, zanonimizowane, przeznaczone do usunięcia itp.) i będzie to realizowane poprzez kierowanie ich do odpowiednich kroków,
- proces do swojego działania będzie potrzebował startowania procesów powiązanych,
- na formularzu z danymi wyświetlane będą dodatkowe informacje takie jak tabele z danymi, zestawienia (wyświetlające np. dane o umowach, urlopach, fakturach)
- konieczne będzie dodawanie załączników
- gdy posiadamy dane umieszczone w pliku Excel, lecz potrzebna nam jest jedna z wyżej wymienionej funkcjonalności. Wtedy to, zamiast w dedykowanym procesie słownikowym, dane wczytane zostaną do samodzielnie skonfigurowanej listy pozycji
Przykłady
Przykładowe słowniki realizowane jako procesy standardowe
Przykładowe procesy służące do przechowywania danych słownikowych, stworzone jako standardowy proces:
Karta pracownika – służy do przechowywania informacji o pracownikach, jest bazą danych dotyczącą zatrudnienia, może przechowywać dane na temat m.in. okresu zatrudnienia, rodzaju umowy itp. Karta pracownika często tworzona jest jako standardowy proces. Nawet jeśli w początkowej fazie wdrażania obsługi systemu służyć ma jedynie przechowywaniu danych, często wraz z jego rozwojem, do obiegu karty dodawane są nowe funkcjonalności, takie jak akceptacja karty pracownika przed jej wprowadzeniem do systemu, wyświetlanie zestawień dotyczących pracownika, dodawanie załączników z dokumentami umowy i badań lekarskich itp.
Przykładowy obieg karty pracownika, który został rozszerzony o dodatkowe funkcje:
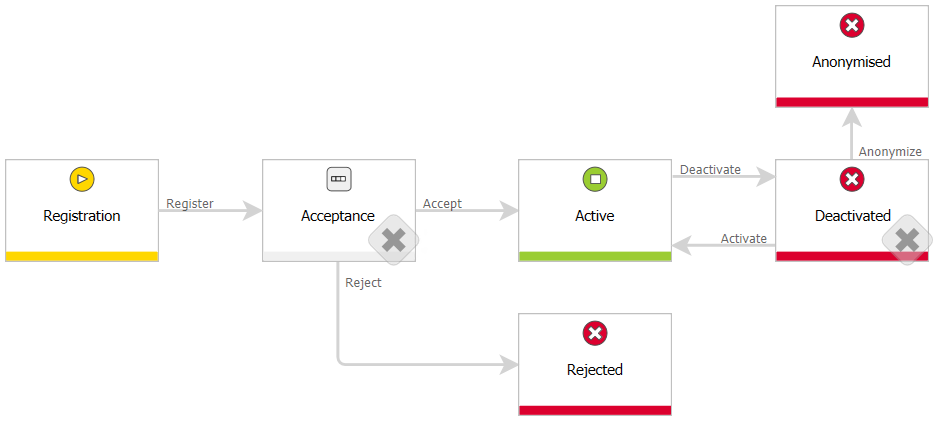
Rysunek 1. Schemat obiegu karty pracownika
Na początku składany jest wniosek o dodanie nowej karty pracownika, osoba akceptująca może taki wniosek zaakceptować lub odrzucić. Aktywna karta może zostać dezaktywowana, skąd może zostać skierowana do anonimizacji (wyczyszczenia danych pracownika), bądź ponownie aktywowana.
Karta Kontrahenta – obieg może wyglądać podobnie do obiegu Karty pracownika. Początkowo może on przechowywać jedynie dane kontaktowe i adres Kontrahenta, lecz przy jego tworzeniu należy zastanowić się, czy w przyszłości nie zaistnieje konieczność dodawania kolejnych funkcjonalności, takich jak dodanie kroków akceptacyjnych, dodawanie dokumentów umów z Kontrahentem w formie załączników, dodanie narzędzi do korespondencji z Kontrahentem itp.
Przykładowe dedykowane procesy słownikowe:
Słownik do przechowywania informacji o flocie samochodów – słownik przechowuje dane takie jak marka, model, opis samochodu i jego stan dostępności (aktywny/nieaktywny). Zestaw danych o poszczególnych autach jest stały, a konieczność dodania – bądź dezaktywacji pojazdu ma miejsce kilka razy w roku. Uzupełniony słownik wygląda następująco:
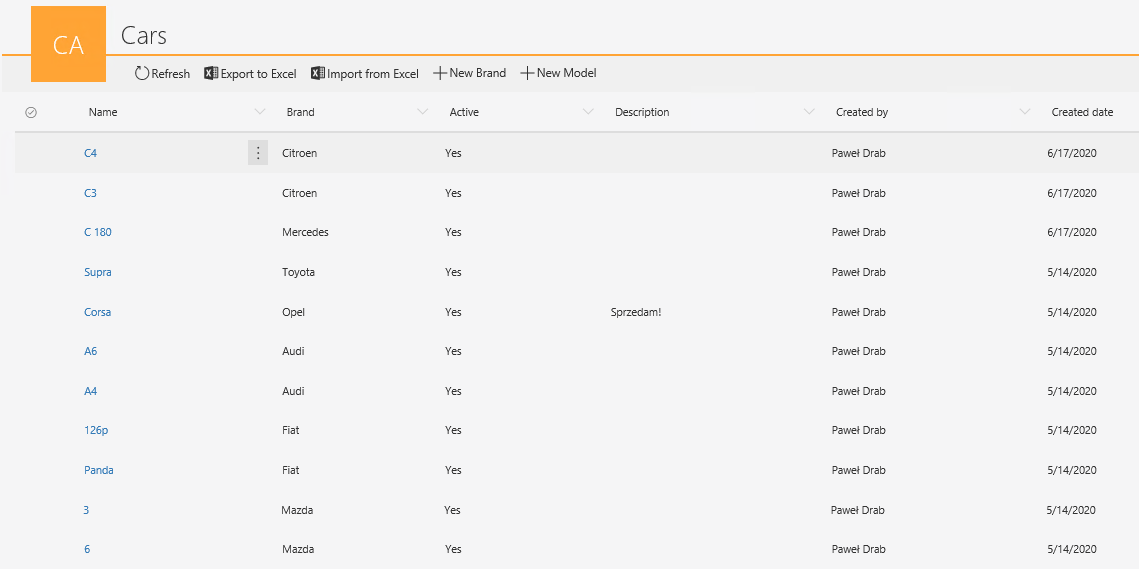
Rysunek 2. Słownik przechowujący dane o flocie samochodów
Słownik z listą krajów świata – słownik przechowuje nazwy wszystkich państw świata oraz informacje, czy dany kraj należy do Unii Europejskiej. Wszystkie te dane projektant procesu ma już w pliku Excel, w związku z czym dodanie ich do słownika nie będzie stanowiło problemu.
Dane w pliku Excel, przygotowane zgodnie z instrukcją z podlinkowanego w akapicie „Proces słownikowy” artykułu. Zgodnie z zaleceniem tam zawartym, schemat tabeli pobrano z raportu przyciskiem „Eksportuj do Excela”:
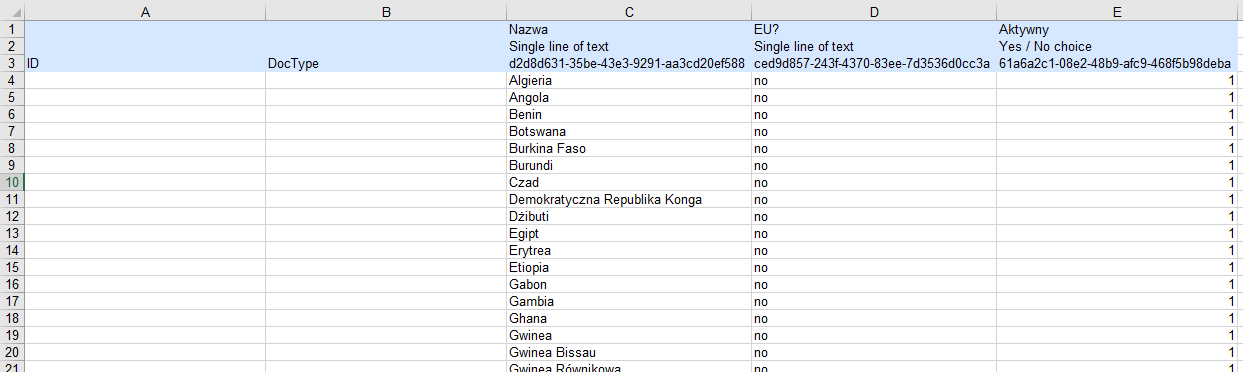
Rysunek 3. Skoroszyt z programu Excel uzupełniony listą krajów
Dodanie wszystkich 252 krajów z listy, przy skorzystaniu z mechanizmu importu danych do słownika zajmuje kilkanaście sekund. Rezultat końcowy:

Rysunek 4. Dane zostały wprowadzone do słownika i można już z nich korzystać
Nadal możemy ręcznie zmieniać dane poprzez formularz, a także poprzez mechanizm importu/exportu z pliku Excel – np. w przypadku, gdy któryś kraj dołączy do wspólnoty europejskiej.
Słownik z listą dań z zakładowej stołówce – w sytuacji, gdyby obsługa zamówień na obiady z zakładowej stołówki realizowana była poprzez obieg, słownik można wykorzystać do przechowywania listy dań dostępnych danego dnia. Zmiana menu ograniczałaby się do wczytania nowej wersji pliku z programu Excel.
Lista dań z dnia wczorajszego przedstawia się następująco:
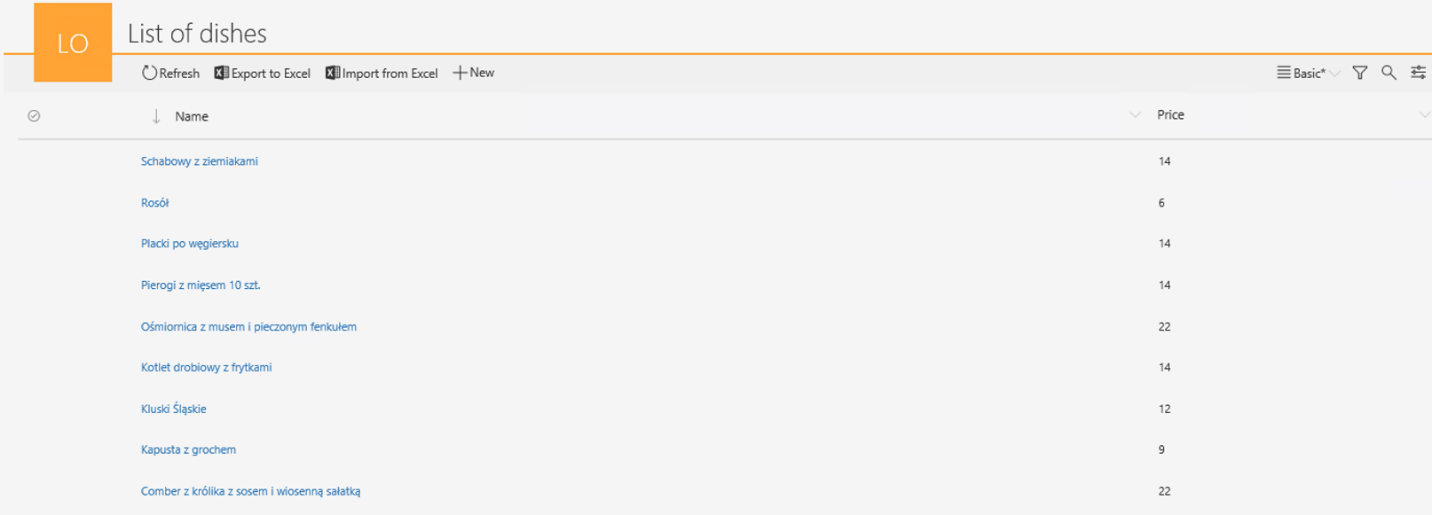
Rysunek 5. Zawartość słownika przed zaktualizowaniem spisu dań
Aby zaktualizować kartę dań, można pobrać plik Excela, następnie zmienić wybrane wartości:

Rysunek 6. Zmiana dań w arkuszu Excel
I ponownie zaimportować plik do słownika:
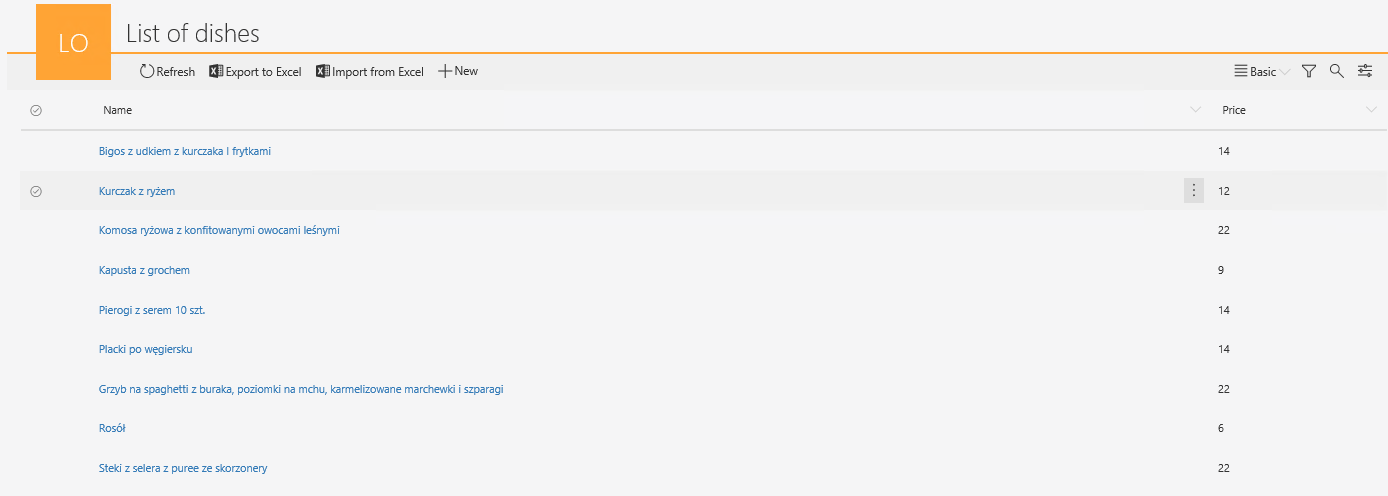
Rysunek 7. Zawartość słownika po zaktualizowaniu dań
Oczywiście nic nie stoi na przeszkodzie, aby wybrane dania lub ceny zaktualizować ręcznie, np. w przypadku gdy zaimportowano dane z błędem.
Dlaczego istotnym jest, aby aktualizować uprzednio pobrany plik Excel (Rysunek 6)? Ponieważ już dodane dane, otrzymują unikatowy identyfikator (GUID) na podstawie którego system wie, które wiersze należy zaktualizować, a które są wierszami nowymi i należy je dodać. Jako przykład po raz drugi zostanie dodany plik Excel z tymi samymi daniami, lecz z nieuzupełnioną kolumną ID:

Rysunek 8. Plik Excela z nieuzupełnioną kolumną "ID"
W raporcie z importu uzyskamy informację, że dodano nowych 9 elementów, dania w karcie zostały zdublowane, a system przypisał im nowe, ich własne numery GUID:

Rysunek 9. Informacja, którą dostajemy po ukończeniu importu danych do procesu słownikowego
Podsumowanie
Obie metody przechowywania danych słownikowych mają swoje zalety, jednak świadomość różnic między nimi może ułatwić dokonanie trafniejszego wyboru, bądź skłonić do zmiany dotychczasowego sposobu ich składowania.
Czy planujecie możliwość określenia sposobu sortowania w automatycznym źródle danych procesu słownikowego?
Nie ukrywam, że brakuje mi tej możliwości.