Dotyczy wersji 2022.1.3 i powyżej, autor: Maciej Kieblesz
Wprowadzenie
W niniejszym artykule opisano metodę utrzymania baz danych w celu zapewnienia możliwie największej wydajności działania silnika SQL, a co za tym idzie samej aplikacji BPS. W praktyce będzie to oznaczało zmniejszenie ilości błędów typu ‘timeout’ na przykład przy ładowaniu się raportu. Mechanizm ten jest dostosowany do baz danych BPS.
Wyłączenie odpowiedzialności:
Webcon nie odpowiada za operacje utrzymania baz danych klientów, jednak zaleca się, aby codziennie poza godzinami biznesowymi tego rodzaju operacje były wykonywane na bazach danych BPS.
W niniejszym artykule wykorzystano ogólnodostępne w publicznym Internecie skrypty open source. Skrypty te są z powodzeniem używane przez WEBCON w instalacjach własnych i wybranych klientów. Należy jednak pamiętać, aby przed ich produkcyjnym użyciem przeprowadzić testy na wydzielonych środowiskach (zalecana procedura dla wszelkich skryptów pobieranych z Internetu).
Podane w artykule przykłady są jedną z możliwych do zastosowania procedur utrzymania baz danych, mogą być modyfikowane w zależności od warunków konkretnego środowiska.
Źródło: rozdział 7.1 dokumentu:
https://community.webcon.com/uploads/editor/dropped/webcon_bps_2021_infrastructure_izFWwC.pdf
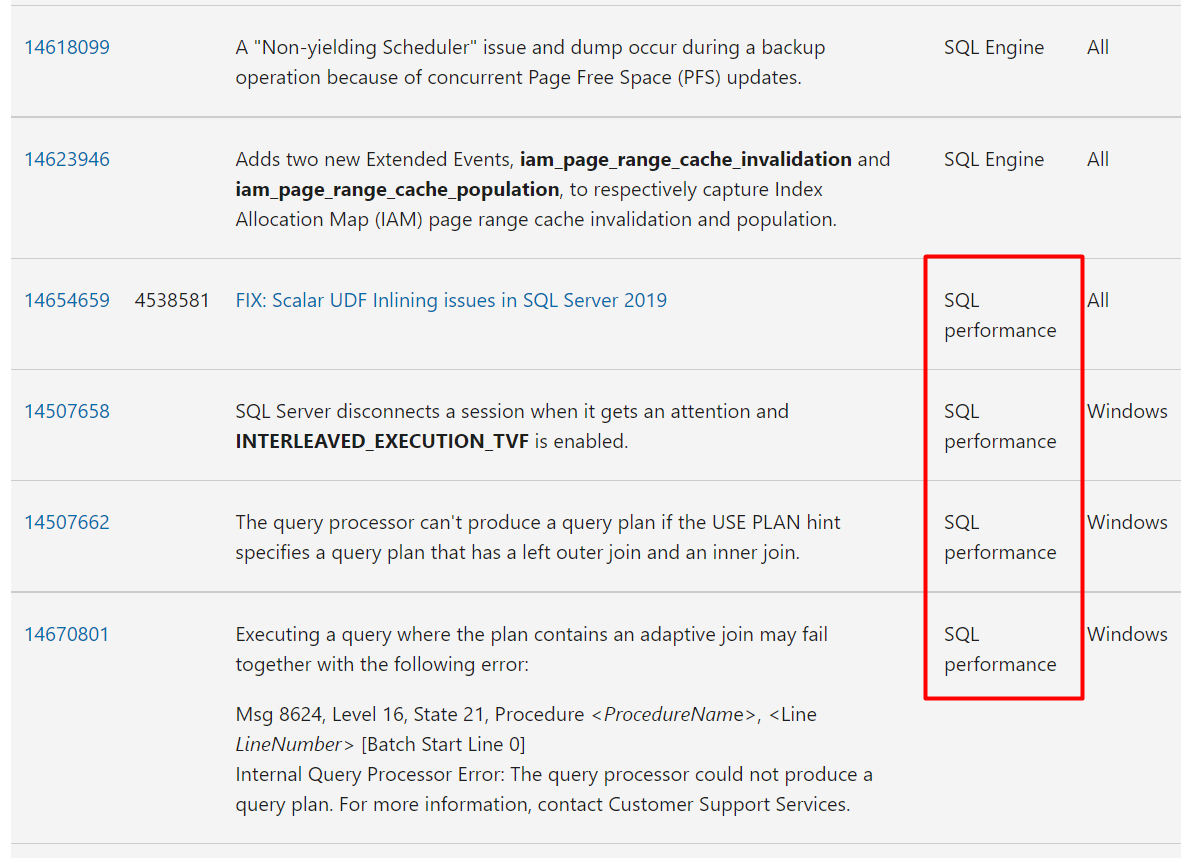
Z uwagi na występujące poprawki w zakresie wydajności samego silnika zaleca się również instalację najnowszych aktualizacji Microsoft SQL Server.
Przykład z Cumulative Update 16 dla SQL Server 2019:
Tworzenie joba
W SQL Server Management Studio istnieje możliwość stworzenia planu utrzymania ręcznie z poziomu interfejsu użytkownika na podstawie odrębnych zadań dostępnych w toolboxie:
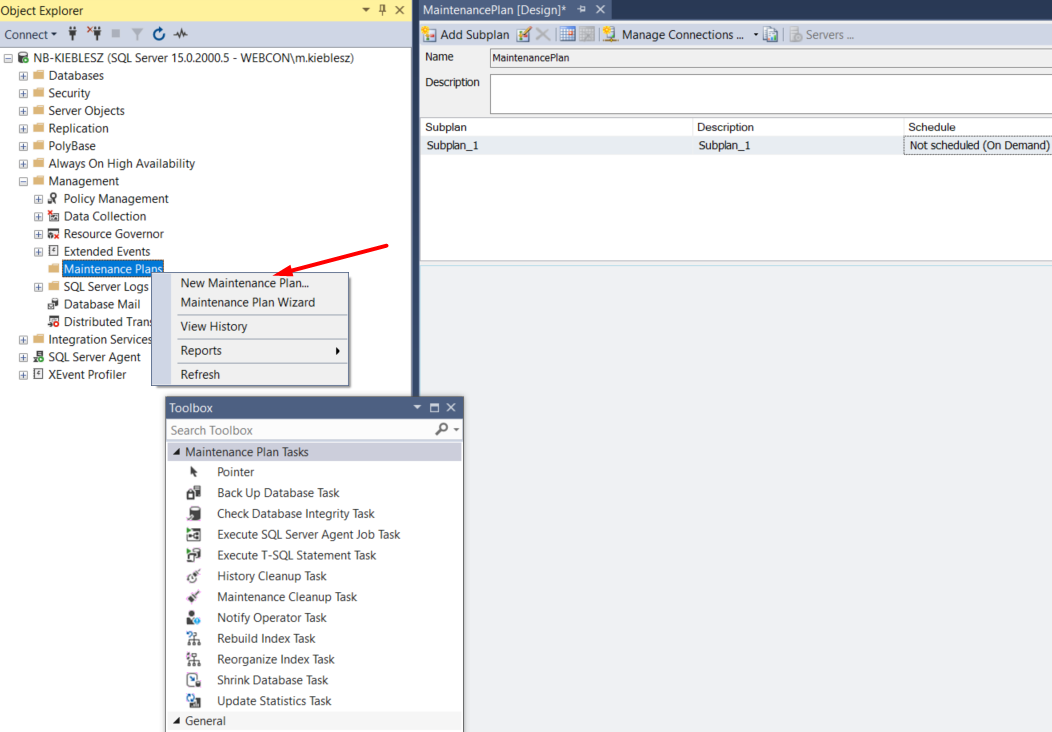
W tym przypadku joba nie należy tworzyć przez interfejs, ale skorzystać z gotowych skryptów open source Ola Hallengrena:
https://ola.hallengren.com/sql-server-index-and-statistics-maintenance.html
W sekcji Download dostępny jest skrypt MaintenanceSolution.sql. Należy go pobrać i wkleić w instancji SQL w oknie nowej kwerendy.
Link umożliwiający bezpośrednie pobranie skryptu:
https://ola.hallengren.com/scripts/MaintenanceSolution.sql
Skrypt należy uruchomić w kontekście bazy danych, w której będą zapisywać się logi wykonanych operacji – można to zrobić domyślnie na nadrzędnej bazie systemowej (master) lub na nowo utworzonej bazie danych. W tym drugim przypadku należy wcześniej utworzyć bazę danych i w skrypcie zmienić polecenie USE [master] na USE [Nazwa_bazy].
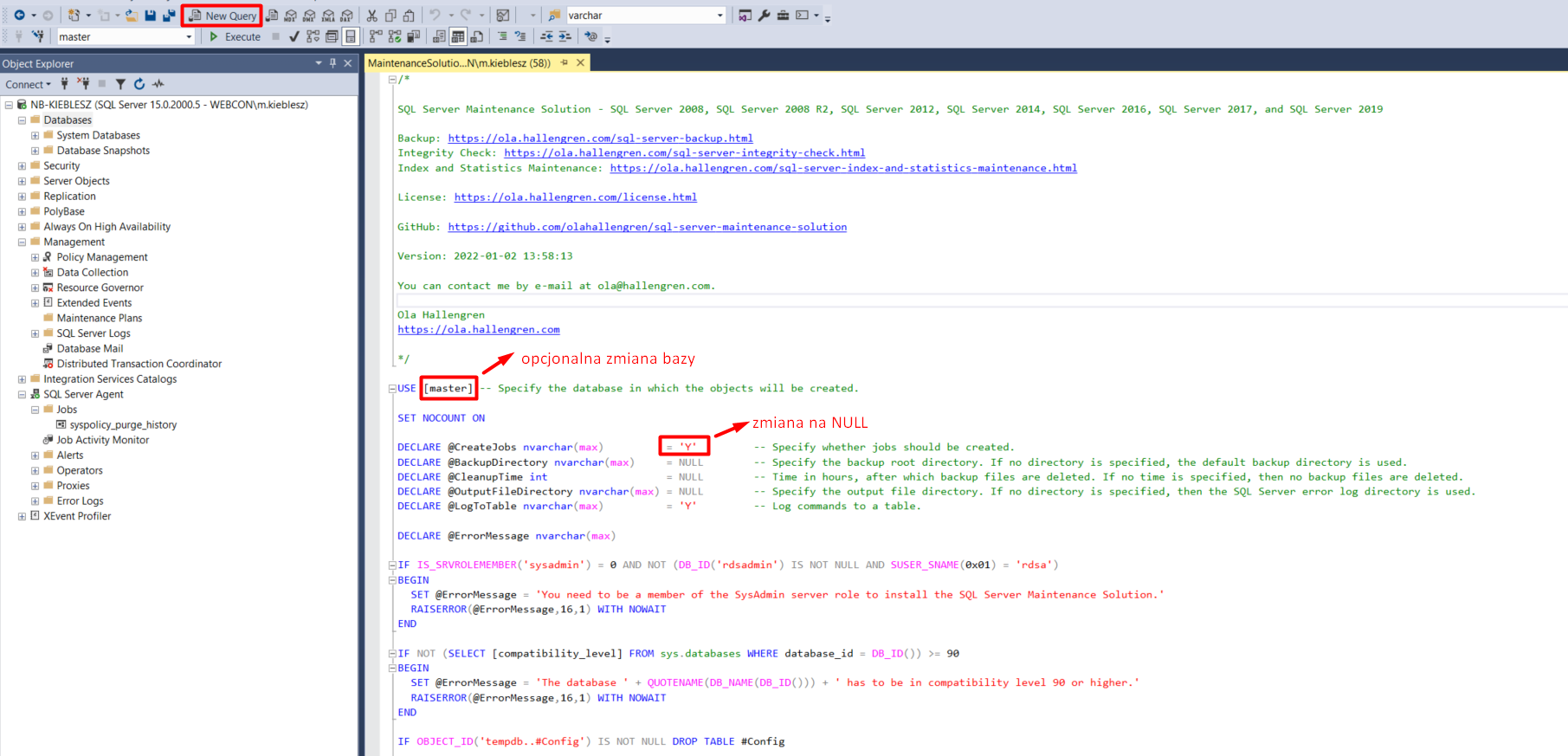
W związku z tym, że pod uwagę brana jest wyłącznie kwestia wydajności, parametr @CreateJobs należy zmienić na NULL, a następnie wykonać skrypt wybierając Execute.
Kolejnym krokiem będzie utworzenie nowego joba, co można łatwo wykonać z poziomu interfejsu:

W zakładce General należy zmienić nazwę joba na taką, która będzie sugerowała, jakie są jego funkcje, np. „Maintenance_Indexes_Statistics”. Możliwa jest tutaj również zmiana konta, w kontekście którego będzie wykonywany job (parametr Owner) – najlepiej, aby był to administrator systemu, np. SA.
Krok 1
W zakładce Steps należy wybrać New, podać nazwę i w polu Command wkleić następujące parametry:
Krok 2
Aby dodać drugi krok, należy postępować w analogiczny sposób, podając jednak inne parametry. Uzupełniając parametr @Databases, użytkownik powinien podać dokładną nazwę bazy zawartości Content BPS, ponieważ tylko w kontekście wskazanej bazy danych wykonywane będą operacje. Tę samą nazwę bazy należy również uwzględnić w parametrze @Indexes, tak aby możliwe było pominięcie tabel, w odniesieniu do których wykonanie operacji Update statistics with FULLSCAN nie jest konieczne. Ponadto statystyki zostały już zaktualizowane z domyślnym próbkowaniem w pierwszym kroku. W teorii tabel jest więcej, ale operacja Update statistics with FULLSCAN tych konkretnych trwa najdłużej w przypadku dużych instalacji BPS (pominięcie tych trzech indeksów pozwala zaoszczędzić około 30 minut trwania joba w przypadku bazy danych o rozmiarze 1 TB – parametr @Indexes dodaje się wyłącznie w celu skrócenia czasu wykonywania joba).
W drugim kroku w zakładce Advanced należy zmienić opcję On success action: z Go to the next step na Quit the job reporting success. Jeśli użytkownik nie dokona takiej zmiany, przy zapisywaniu joba otrzyma odpowiedni monit, po zatwierdzeniu którego zmiana nastąpi automatycznie. Krok ten będzie odpowiadał za wykonanie zadania Update Statistics z opcją FULLSCAN dla statystyk dotyczących indeksów. Opcja FULLSCAN w dużym stopniu wpływa na wydajność.
Krok 2 – Modyfikacja dla silnika SQL w nowszych wersjach SQL Server
Wraz z wersją SQL Server 2016 SP1 Cumulative Update 4 pojawiła możliwość dodania do komendy aktualizującej statystyki opcji PERSIST_SAMPLE_PERCENT = ON, która zapobiega utracie zdefiniowanego próbkowania po autoaktualizacji statystyk.
Wdrożenie tego mechanizmu będzie wymagało zmiany procedury IndexOptimize poprzez uruchomieniu podlinkowanego skryptu w kontekście bazy, na której został uruchomiony skrypt MaintenanceSolution.sql
oraz dodania jednego parametru do wykonania Kroku 2:
@CurrentStatisticsPersistedSample = 'Y',
EXECUTE dbo.IndexOptimize
@Databases = 'BPS_Content_PROD',
@FragmentationLow = NULL,
@FragmentationMedium = NULL,
@FragmentationHigh = NULL,
@UpdateStatistics = 'INDEX',
@LogToTable = 'Y',
@StatisticsSample=100,
@CurrentStatisticsPersistedSample = 'Y',
@Indexes = 'ALL_INDEXES, -BPS_Content_PROD.dbo.WFHistoryElements, -BPS_Content_PROD.dbo.WFHistoryElementDetails, -BPS_Content_PROD.dbo.WFActionExecutions, -BPS_Content_PROD.dbo.SolrIndexerQueueItems'
Harmonogramy
Należy stworzyć odpowiedni harmonogram wykonywania zadania utrzymaniowego – najlepiej, aby było wykonywane poza godzinami biznesowymi.
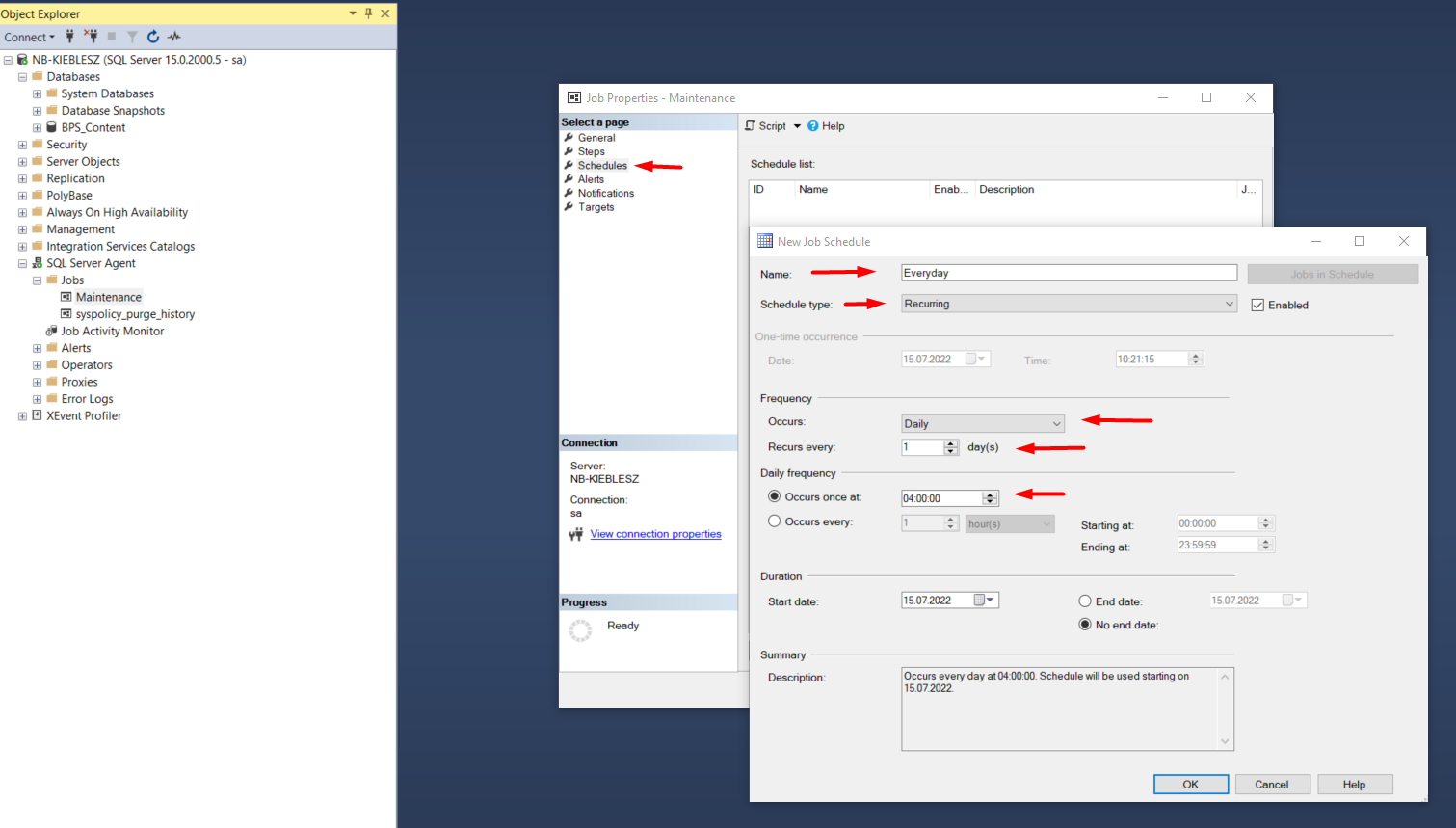
Wprowadzone zmiany należy zatwierdzić przyciskiem OK.
Wpływ innych ustawień na wydajność silnika SQL
Poza Maintenance, na wydajność silnika SQL wpływ będą miały również inne ustawienia instancji SQL, np. parametr MaxDOP, który (według Microsoft) powinien być ustawiony zgodnie z wersją SQL Server, liczbą węzłów NUMA oraz liczbą procesorów logicznych, tak jak podano w tabelach w artykule: Configure the max degree of parallelism (server configuration option) – SQL Server | Microsoft Learn .
Cost Threshold for Parallelism – domyślna wartość „5” może okazać się za mała. W tym przypadku zalecenia są różne, a według jednego z nich wartość parametru równoległego wykonywania planu utrzymania nie powinna być niższa niż 50. Microsoft nie podaje oficjalnych wytycznych w tym zakresie i wskazuje na konieczność dostosowania parametru do określonej instancji SQL po przetestowaniu różnych konfiguracji.
Liczba plików mdf/ndf bazy systemowej Tempdb powinna odpowiadać liczbie VPCU (nie więcej niż 8). Są to ustawienia instancji SQL, jednak należy pamiętać, że na wydajność silnika wpływ mają fizyczne parametry maszyny SQL – szybkość dysków (IOPS) lub procesorów, a także pamięć RAM.
Integralność i tworzenie kopii zapasowych baz danych
W innych zakładkach na swojej stronie Ola Hallengren opisuje rozwiązania służące do sprawdzania integralności baz danych i do tworzenia kopii zapasowych.
Każdy administrator bazy danych powinien samodzielnie zadbać o backupy pełne, różnicowe i loga, tak aby w sytuacjach kryzysowych możliwe było odtworzenie bazy danych, niezależnie od czasu wystąpienia awarii.
Więcej informacji na temat tworzenia kopii zapasowych dostępnych jest na stronie:
https://docs.microsoft.com/en-us/sql/t-sql/statements/backup-transact-sql?view=sql-server-ver16
Administrator powinien także dokonać weryfikacji integralności bazy danych (checkdb) w celu wczesnego wykrycia tak zwanej „korupcji” bazy danych:
Odtworzenie bazy danych z uszkodzonej kopii zapasowej nie będzie możliwe.