Dotyczy wersji 2017.1.3.x; Autor: Bartłomiej Spyrka
Konfiguracja procesów i źródeł danych pod kątem RODO
1. Informacje wstępne
Zawartością bieżącego artykułu jest wiedza, pozwalająca na skonfigurowanie składowych – potrzebnych do skonfigurowania systemu opartego o WEBCON BPS, pod kątem regulacji nakładanych przez RODO.
Podążając za treścią artykułu czytelnik dowie się:
- Czym są słowniki danych osobowych w BPS,
- Jakie występują rodzaje słowników danych osobowych i jak je skonfigurować
- Jak określić zawartość poszczególnych procesów jako dane wrażliwe
- W jaki sposób wygenerować raport prezentujący przechowywanie danych osobowych z BPS
Na wstępie warto podkreślić, iż wprowadzenie RODO wprowadza zmiany w zakresie ochrony danych osobowych, ale nie narzuca ścisłych reguł jakie muszą zostać zrealizowane w konkretnej firmie. Prezentowane dalej rozwiązanie niej jest gotowym końcowym rozwiązaniem – a jedynie przykładem – na którym można się oprzeć przy dokonywaniu konfiguracji aby firma działała wedle reguł RODO.
2. Źródła danych osobowych i ich konfiguracja
2.1. Opis
W tym rozdziale – podane zostaną przykłady – utworzenia źródeł danych osobowych – możliwych do wykorzystania w BPS przy okazji dostosowywania instalacji pod regulacje RODO.
W BPS wyróżnimy dwa rodzaje źródeł danych osobowych:
- Źródła oparte o proces
- Źródła, które nie są oparte o proces
Oba rodzaje źródeł muszą zawierać ten sam zestaw składowych określających:
- Określenie źródła – jako źródło danych osobowych
- Unikalny Identyfikator w źródle
- Kolumny źródła danych osobowych
Konfiguracja powyższych – w zależności od rodzaju (procesowe / nie procesowe) jest różna – natomiast sprowadza się do tego samego efektu w BPS.
2.2. Źródła danych procesowe
Źródłem danych osobowych w postaci procesowej nazwiemy proces, który posiada:
- Identyfikator w postaci WFD_ID
- Oznaczenie procesu jako słownik danych osobowych
- Posiadanie przynajmniej jednego atrybutu w definicji procesu oznaczonego jako nośnik danych osobowych
Jako przykładowy proces źródła danych osobowych RODO, możemy rozważyć proces Osoby kontaktowej opartej o założenia:
- Jedna instancja w procesie oznacza jedną osobę kontaktową
- WFD_ID to unikalny identyfikator osoby kontaktowej
- Proces posiada atrybuty zawierające dane osobowe:
- Imię
- Nazwisko
- Telefon
- Adres email
- Proces posiada skonfigurowane Ustawienie RODO (oznaczenie ‘Proces jest słownikiem danych osobowych’) oraz zdefiniowany tryb czyszczenia.
Konfiguracji dokonujemy kolejno:
- Ad. 1 – wynika z architektury przyjętego rozwiązania – nie wymaga dodatkowej konfiguracji
- Ad. 2 – wynika z architektury przyjętego rozwiązania – nie wymaga dodatkowej konfiguracji
- Ad. 3 – Każdy z atrybutów, będących nośnikiem danych osobowych – oznaczmy poprzez zakładkę Styl i zachowanie (sekcja Przechowywanie danych osobowych)
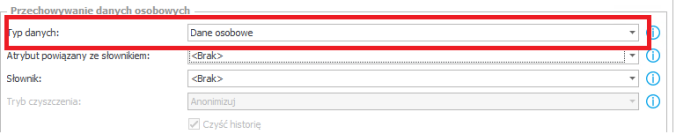
- Typ danych ( Dane osobowe / Dane wrażliwe ) – nie ma w tym miejscu znaczenia. Istotne jest wskazanie któregokolwiek ( [Typ danych musi być <> ‘Standardowe’ )
- Na procesie może istnieć X atrybutów z czego Y określamy jako dane osobowe (X>=Y)
- UWAGA! Jeżeli atrybut / kolumna jest oznaczona w następujący sposób:
- Wskazany jest niestandardowy typ danych (dane osobowe lub wrażliwe)
- Wybrany jest "Atrybut powiązany ze słownikiem" LUB "Słownik"
Pole NIE BĘDZIE BRANE pod uwagę jako pole, w którym szukamy zawartości podanych przez zgłaszającego w akcji szukającej dopasowania (jedna z akcji SDK opisana w innym artykule na KB)
Powyższe powiązanie ma zastosowanie do instancji w których występuje ID danej osoby (zatem brane jest pod uwagę do wykonywania operacji np. anonimizacji danych) szerzej opisane w rozdziale 3. Wskazanie procesów do obsługi poprzez mechanizmy wspierające RODO
- Ad. 4 – Oznaczenie procesu jako źródło danych osobowych
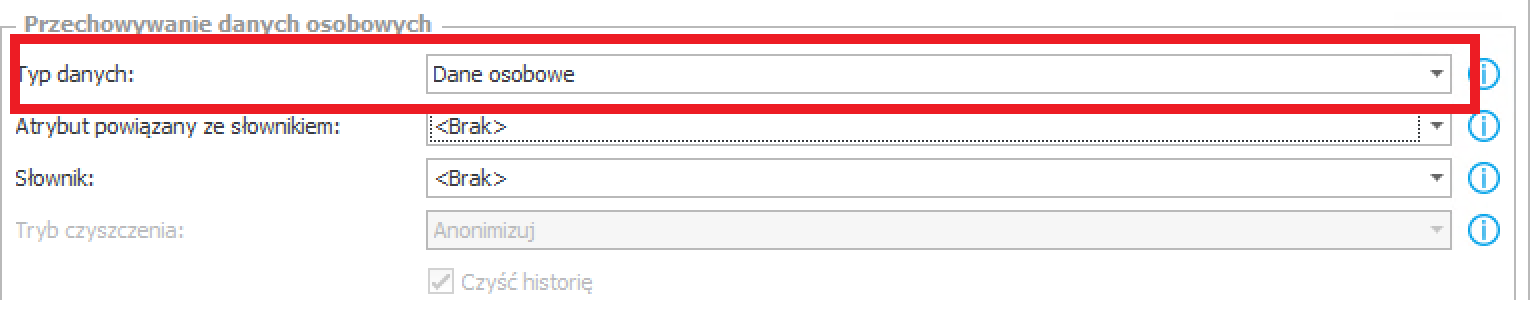
Proces przygotowany w taki sposób może stanowić źródło danych innych procesów, gdzie wykorzystuje się powiązanie z osobą kontaktową – np. osoba odpowiedzialna za umowę, osoba uczestnicząca w spotkaniu rekrutacyjnym itd.
Umieszczenie identyfikatora osoby ( w tym przypadku WFD_ID) ma olbrzymie znaczenie podczas przeszukiwania bazy, pod kątem wystąpienia elementów obiegu ( Wfelementów) które zawierają wskazane przez administratora identyfikatory osób.
2.3. Źródła danych zewnętrzne
Zewnętrznym źródłem danych osobowych będzie źródło posiadające:
- Oznaczenie 'Źródło zawiera dane osobowe'
- Wyznaczony identyfikator danych osobowych, występującego w źródle (analogia do WFD_ID ze źródła procesowego)
Konfiguracji dokonuje się poprzez wykonanie kilku czynności w zakładce Źródła danych:
- Na poziomie konkretnego źródła ( np. MSSQL) – należy zwrócić uwagę na elementy oznaczone czerwoną ramką
- Źródło musi posiadać oznaczony checkbox ‘Źródło zawiera dane osobowe’
- Źródło musi posiadać istniejącą w źródle danych kolumnę która posłuży jako identyfikator dla BPS.
- Aby pobrać listę dostępnych kolumn – należy użyć przycisku dostępnego oznaczonego niebieską ramką na zrzucie poniżej

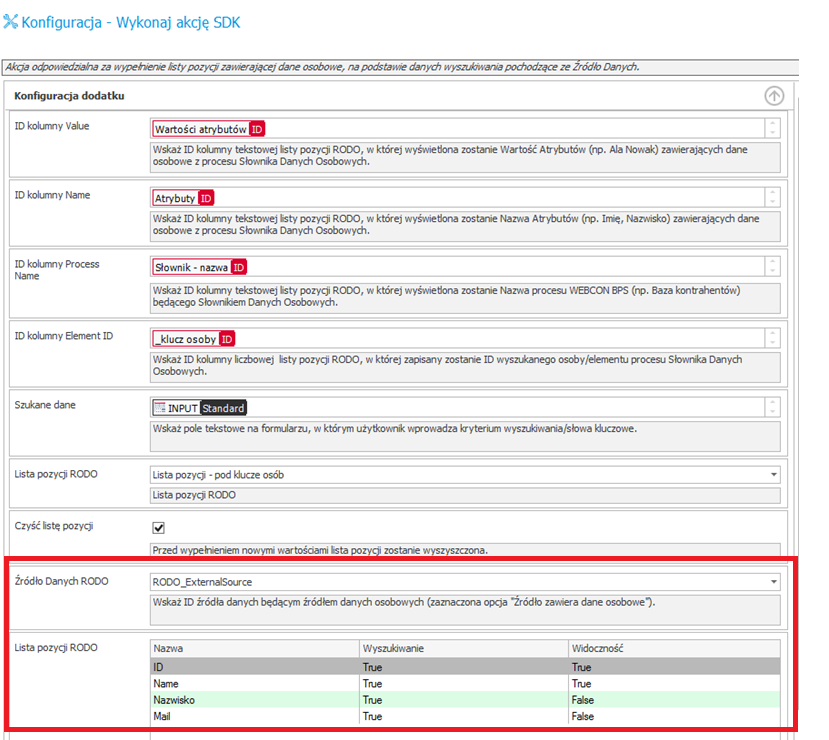
Na tym konfiguracja zewnętrznych źródeł danych się kończy. W przypadku chęci przeszukiwania tego rodzaju źródeł danych celem odnalezienia identyfikatora ( np. w ERP) – należy dokonać konfiguracji w akcji SDK przeszukującej dane źródło, oraz wykonać mapowanie pól po stronie akcji (opisane w innym artykule na KB – poniżej przykładowy zrzut ekranu).
3. Wskazanie procesów do obsługi poprzez mechanizmy wspierające RODO
3.1. Opis
Jako uzupełnienie powyższego rozdziału, poniżej podaje przykład praktycznego podejścia do skonfigurowania procesu. Celem nadrzędnym jest aby akcje modyfikujące zawartość źródła danych (dane osobowe) poprawnie znalazły poszukiwane frazy.
Udostępnienie danych (w konkretnym procesie), do powiązania z identyfikatorem osoby (ze słownika) wykonuje się poprzez:
- Oznaczenie co najmniej jednego atrybutu / kolumny na liście pozycji jako przechowujący dane osobowe / wrażliwe
- Wybór słownika przechowującego klucz (identyfikator) osoby, ze źródła danych
- Wskazanie trybu czyszczenia danych osobowych
3.2. Konfiguracja
Celem wykonania konfiguracji – zakładamy istnienie procesu wykorzystującego dane pochodzące ze źródła danych osobowych (w naszym wypadku Osoby kontaktowe).
- Na procesie wykorzystującym dane osobowe – posiadamy atrybuty gdzie jednym z nich jest atrybut słownikowy – wykorzystujący źródło danych osobowych
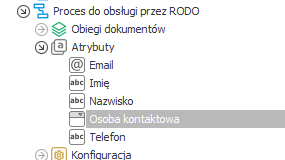
- Na atrybucie Osoba kontaktowa – wykorzystujemy standardowa funkcję „Pole Docelowe” dostępną w konfiguracji pickera – automatycznie ustawiamy pozostałe pola formularza (imię, nazwisko etc.) za pomocą wyboru wartości w tym polu. Skutkiem takiego działania jest przechowywanie danych osobowych – pochodzących ze źródła danych osobowych (słownik) – w innych elementach obiegu innych procesów. Oznacza to, że dane mogą być rozpropagowane w wielu miejscach systemu.
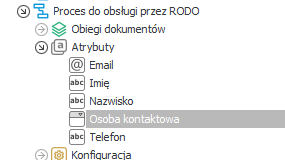
- Kolejnym krokiem, jaki należy wykonać jest – oznaczenie atrybutów na procesie, które przechowują dane osobowe. W myśl przykładu będą to odpowiednio:
- Osoba kontaktowa – picker
- Imię – pole tekstowe
- Nazwisko – pole tekstowe
- Telefon – pole tekstowe
- Email – pole tekstowe
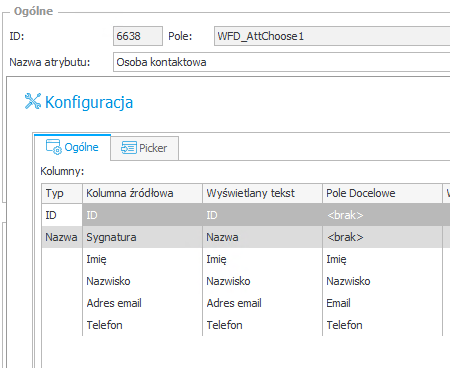
Konfigurację wykonujemy następująco:
- Osoba kontaktowa
- W typie danych wskazujemy dane osobowe / wrażliwe
- Koniecznie – wskazujemy zasilenie słownikiem danych osobowych ( Osoba kontaktowa) – do wyboru znajdziemy Procesy WEBCON BPS oznaczone jako słowniki danych osobowych, oraz źródła danych skonfigurowane jako zawierające dane osobowe.
- Tryb czyszczenia – pobierany jest na podstawie konfiguracji słownika, z możliwością nadpisania ustawienia

- Pola nie będące słownikami tylko polami np. tekstowymi
- Ustawiamy jako nośnik danych osobowych / wrażliwych
- W polu „Atrybut powiązany ze słownikiem” wskazujemy wcześniej skonfigurowany picker (Osoba kontaktowa) – tzn. wskazujemy pole słownikowe, z którego konfigurowany atrybut będzie czerpał wartość.
- W przypadku pól podstawowych, nie ma możliwości nadpisania trybu czyszczenia. Pobierany jest on z poziomu atrybutu powiązanego ze słownikiem

- Analogiczną operację, należy wykonać na wszystkich polach będących nośnikami danych osobowych.
4. Generacja raportu
4.1. Opis
Wykonanie powyżej opisanych prac w ujęciu do każdego z procesów występujących na bazie danych pozwoli na stworzenie efektu końcowego w postaci dokumentu, podsumowującego:
- Słowniki danych osobowych występujących w danej bazie danych
- Procesy wykorzystujące dane osobowe – wraz z atrybutami które zawierają dane osobwe
4.2. Generacja raportu
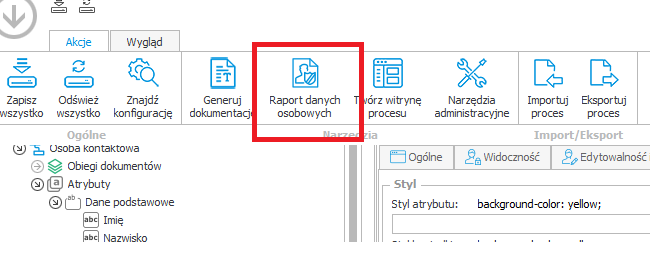
Celem wygenerowania raportu, należy użyć wstążki dostępnej w WEBCON Designer Studio.
Po uruchomieniu programu, w zakładce Akcje, wybieramy ‘Raport danych osobowych‘ i w sposób analogiczny do generacji dokumentacji należy wskazać szablon, język oraz ścieżkę, do której ma zostać wygenerowany raport.
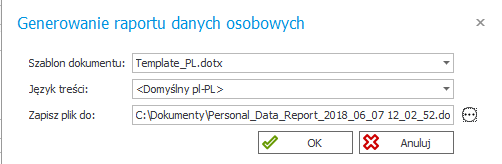
Poniżej przedstawiono fragment przykładowo wygenerowanego raportu
5. Podsumowanie
Powyższy przykład konfiguracji – pozwala w prosty sposób dostosować obiegi do przepisów RODO. Określenie, uporządkowanie i ujednolicenie źródeł danych oraz określenie powiazań i umiejscowienia przetrzymywania danych osobowych z pewnością będzie wyzwaniem organizacyjnym – ale z drugiej strony, pozwoli zadbać o porządek i przejrzystość w systemie, pozwalając w prosty sposób zbiorczo przedstawić konfigurację dostępną w systemie.
