Dotyczy wersji 2017.1.3.x; Autor: Bartłomiej Spyrka
Konfiguracja SDK dla procesu przeszukiwania bazy BPS pod kątem RODO
1. Informacje wstępne
Niniejszy artykuł przedstawia sposób w jaki można wykorzystać funkcjonalności dostępne w wersji 2017.1.3.x do przygotowania procesu . Podążając za treścią artykułu czytelnik dowie się:
- W jaki sposób podejść do procesu Administracyjnego – pozwalającego na rozpoznanie użytkownika w danym źródle danych
- Jakie elementy z WEBCON BPS można wykorzystać przy budowie procesu
- Jak skonfigurować SDK i akcje powiązane z RODO
- Jak wykonać usunięcie / anonimizację danych w procesach BPS
- Jak zebrać informacje o zgromadzonych danych osobowych
- W jaki sposób pobrać informację o danych i ilościach miejscach wykorzystywania danych osobowych z procesów
Na wstępie warto podkreślić, iż wprowadzenie RODO wprowadza zmiany w zakresie ochrony danych osobowych, ale nie narzuca ścisłych reguł jakie muszą zostać zrealizowane w konkretnej firmie. Prezentowane dalej rozwiązanie nie jest gotowym końcowym rozwiązaniem – a jedynie przykładem – na którym można się oprzeć przy dokonywaniu konfiguracji aby firma działała według ustaleń RODO.
1.1. Idea
Przebieg całego workflow przedstawiony jest na poniższym schemacie. Artykuł nie traktuje o konfiguracji całego procesu, ponieważ może być on kształtowany dowolnie przez osobę go modelującą.
W artykule skupimy się na elementach konfiguracji które są dedykowanymi do RODO – sposobie ich konfiguracji i przykładzie użycia.
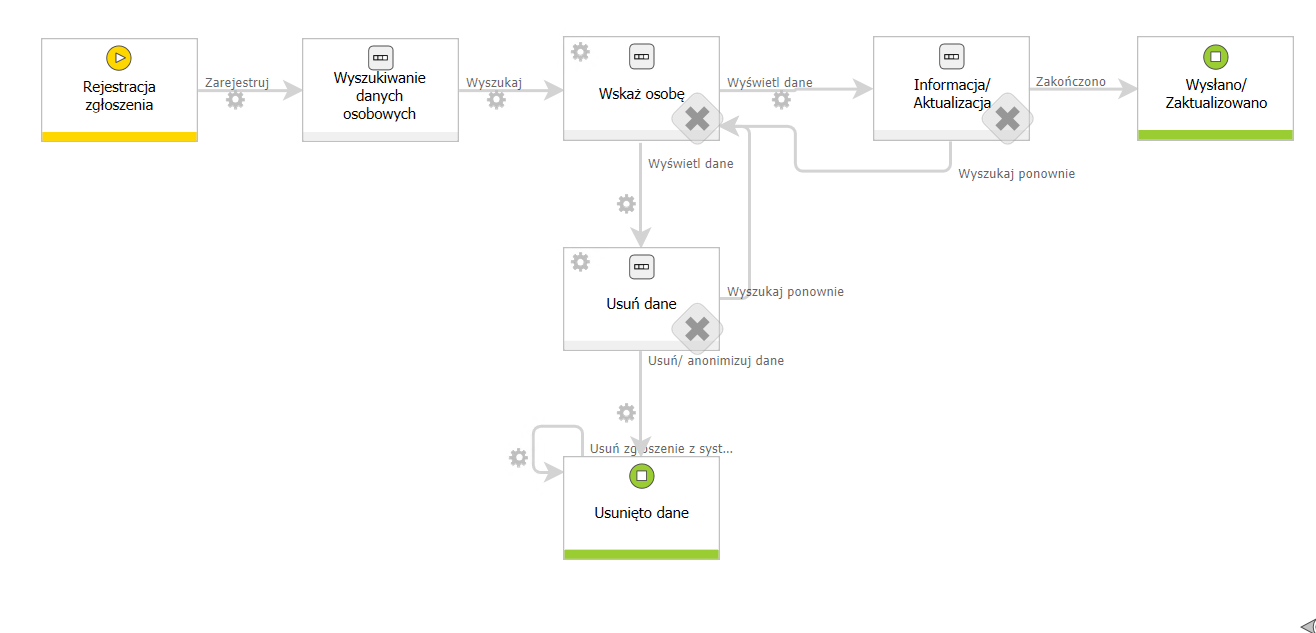
W dalszej części – skupimy się na przejściu elementu przez ścieżkę:
- Rejestracji wniosku – wprowadzenie podstawowych danych
- Wyszukaniu danych osobowych
- Tutaj pokażemy, w jaki sposób przeszukać źródło danych i zapisać wyniki na formularzu
- Wybór osoby – określenie, kogo konkretnie z wskazanej puli dotyczyć będzie dalsze procesowanie
- Usunięcie danych – końcowy etap w którym finalnie wykonuje się operacja anonimizacji / usunięcia danych
1.2. Akcje i dodatki
W ramach najnowszej wersji BPS 2017.1.3.x – po instalacji otrzymają Państwo do dyspozycji dedykowany zestaw SDK do obsługi RODO / GDPR. Wszystkie dodatki znajdą się w klasie WebCon.WorkFlow.Extensions.GDPR.
Udostępniono:
- 4 akcje SDK – pozwalających na operowanie na zbiorach danych
- 1 akcję – anonimizacji / usuwnaia danych
- 3 Custom źródła – pozwalające na dostarczenie danych, do kontrolek raportowych Tabela danych (SQL Grid)
1.2.1. Akcja przeszukującą źródła danych osobowych procesowe (oparte o proces BPS)
WebCon.WorkFlow.Extensions.GDPR.Actions.FillPersonalDataItemList
1.2.2. Akcja przeszukującą źródła danych osobowych zewnętrzne (inne niż proces BPS)
WebCon.WorkFlow.Extensions.GDPR.Actions.FillPersonalDataItemListCustomData
1.2.3. Akcja usuwającą załączniki wraz z historią
WebCon.WorkFlow.Extensions.GDPR.Actions.RemoveAttachmentWithHistoryAction
1.2.4. Akcja zapisu wskazanych identyfikatorów osób, do pól technicznych
WebCon.WorkFlow.Extensions.GDPR.Actions.SaveIdsToTechnicalField
1.2.5. Custom źródło – zgromadzenie danych osobowych
WebCon.WorkFlow.Extensions.GDPR.DataSources.DictionaryDataReportDataSource
1.2.6. Custom źródło – wykorzystanie danych osobowych
WebCon.WorkFlow.Extensions.GDPR.DataSources.ElementsGridDataSource
1.2.7. Custom źródło – wykorzystanie zewnętrznych źródeł danych osobowych
WebCon.WorkFlow.Extensions.GDPR.DataSources.ExternalElementsGridDataSource
1.2.8. Akcja – usuń dane osobowe
Akcja jest dostępna w standardowy sposób ( analogicznie jak np. ‘Zmień wartość pola’)
2. Przykład przebiegu i konfiguracji
2.1. Krótki przebieg procesu

Rysunek 1. Krok rejestracyjny – wstępne wprowadzenie zgłoszenia.
Na pierwszym kroku utworzono formularz zawierający bardzo podstawowe dane. Na jego podstawie osoba zajmująca się obsługą zgłoszenia powinna mieć możliwość wyodrębnienia kluczowych elementów, po których nastąpi przeszukanie słowników oraz zawartości bazy danych.
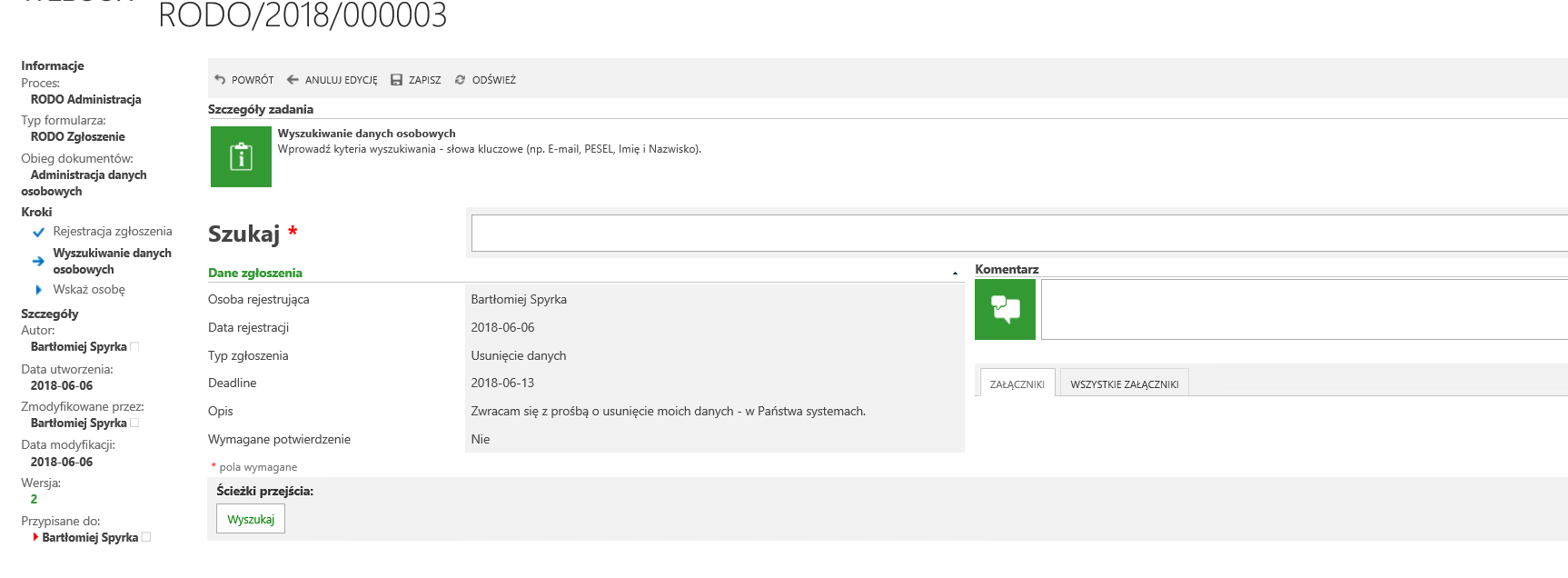
Rysunek 2. Wyszukiwanie danych osobowych
W kolejnym etapie, osoba zajmująca się obsługą zgłoszeń powinna:
- Wprowadzić słowa kluczowe po których nastąpi próba identyfikacji poszukiwanej osoby
- Słowa wprowadzamy w polu ‘Szukaj’
- Kluczowe słowa wprowadzamy w odstępie po ‘spacji’ np. „Jan Kowalski 88332203377”
- Odstęp między słowami kluczowymi ma znaczenie, ponieważ system bierze pod uwagę każde wprowadzone słowo i przeszukuje je odrębnie – a nie łącznie tj. jeśli znajdzie wystąpienie przynajmniej jednego z powyższych słów – wyświetli wynik ( nie jest konieczne wystąpienie kompletu wprowadzonych danych)
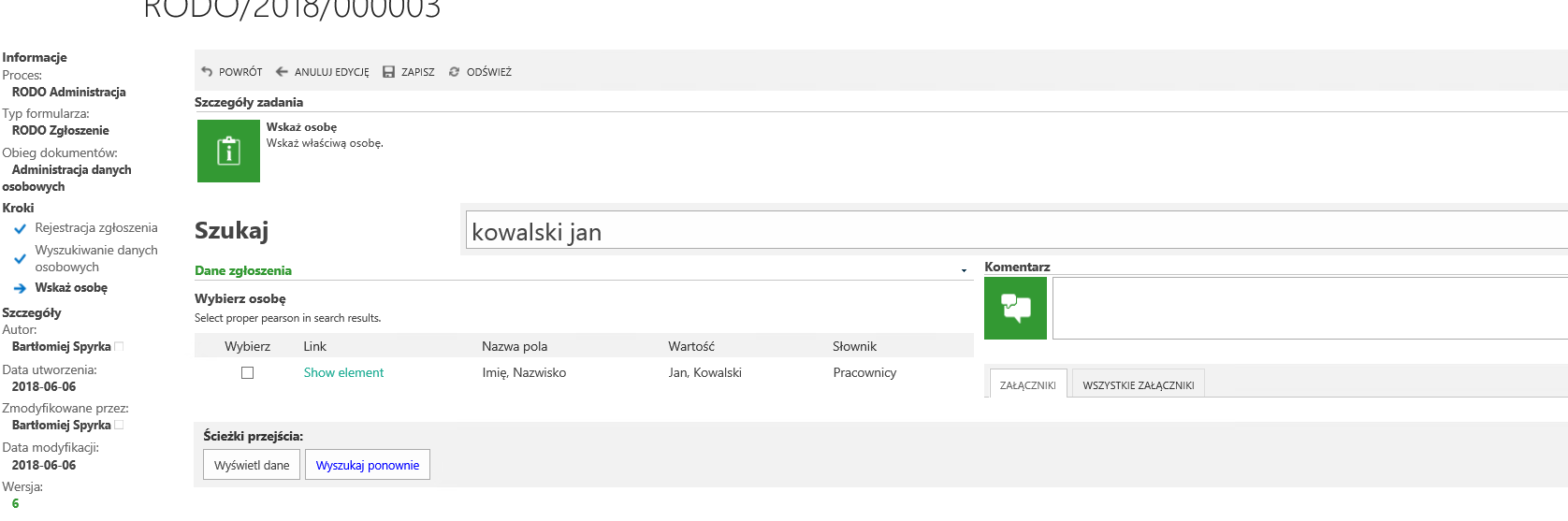
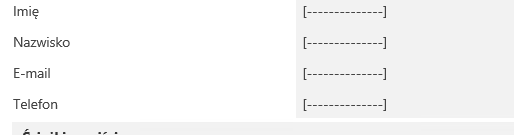
Rysunek 3. Wyniki wyszukiwania frazy
Jak widać, na powyższym zrzucie, wprowadzone dane „kowalski jan” ( wielkość znaków nie ma znaczenia), zostały zagregowane na liście pozycji ( ‘Wybierz osobę’). W przypadku odnalezienia więcej niż jednego dopasowania – pojawi się odpowiednio więcej rekordów – te zostaną dodane do tabeli.

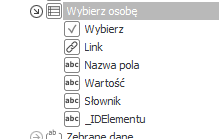
Rysunek 4. Tabela z wynikami wyszukiwania
Tabela zawiera kolumny:
- Wybierz – kolumna checkbox – będzie służyć do zaznaczenia zidentyfikowanego rekordu, który chcemy obsłużyć w dalszej kolejności.
- Link – prowadzi do instancji w obiegi workflow ( jeśli zidentyfikowany wiersz należy do słownika wykonanego na procesie w BPS )
- Nazwa pola – zawiera kolumny, w których odnalezione zostały szukane wartości (w tym wypadku imię i nazwisko)
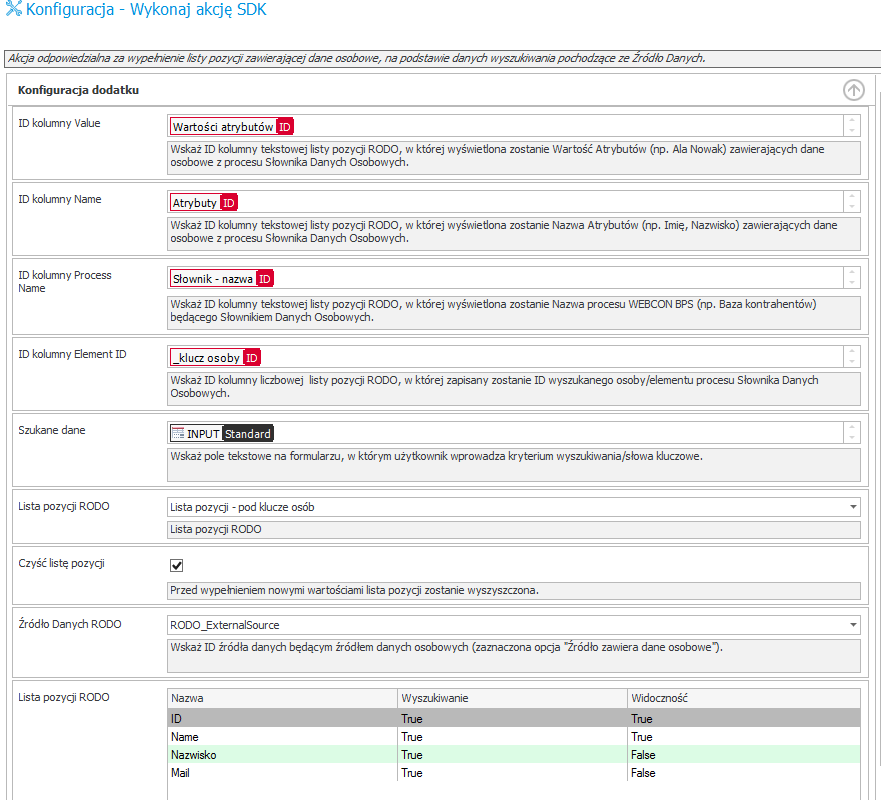
- Wartość – zawartość pól, określonych w kolumnie z Nazwą pola
- Słownik – określa nazwę słownika danych osobowych, w którym odnaleziono dany rekord
Dalszy przebieg procesu, powinien móc zapisać wybrane przez administratora klucze osób, zaprezentować odszukane dane w formie tabelarycznej i przystąpić do Anonimizacji / Usunięcia danych.
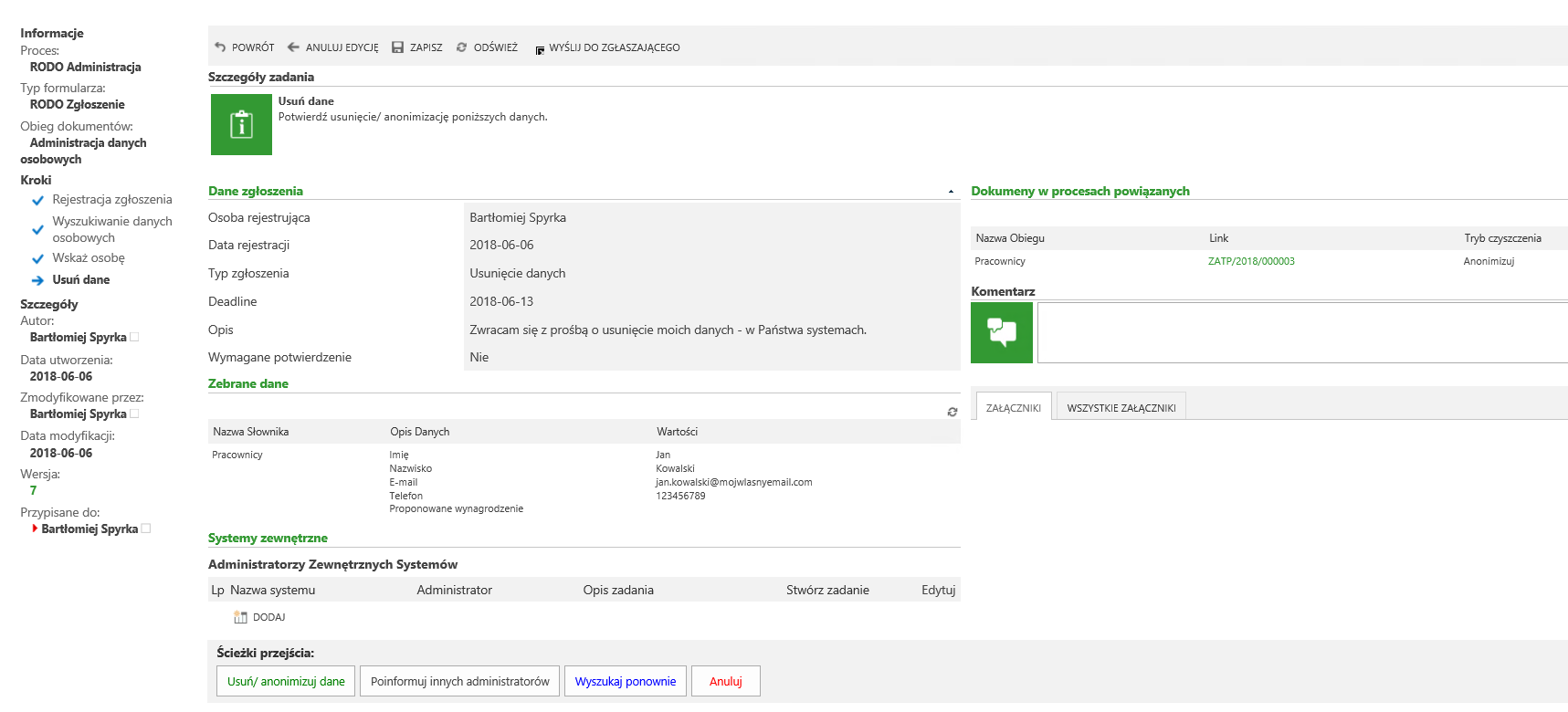
Rysunek 5. Widok formularza tuż przed przesłaniem wykonaniem operacji anonimizacji / usunięcia.
Kolejne wywołanie przejścia ścieżką spowoduje wywołanie akcji operującej na danych osobowych – zgodnie z konfiguracją.
Na słowniku ( dotyczy tylko słowników opartych o proces BPS) – wynik anonimizacji na elemencie słownika wygląda następująco:
Rysunek 6. Wynik wykonania anonimizacji na elementach wykorzystujących dane ze słownika danych osobowych
2.2. Konfiguracja w BPS
Do stworzenia możliwości zapisywania zidentyfikowanych rekordów należy:
- Utworzyć pole tekstowe w którym umieścimy słowa kluczowe ( Input / szukaj)
- Utworzyć listę pozycji z kolumnami
- Lista pozycji ma bardzo prostą konstrukcję – w przypadku przeszukiwania źródła danych będących procesem BPS – można utworzyć kolumnę techniczną – przechowującą ID elementu (WFD_ID) a następnie na poziomie kolumny link – utworzyć hiperłącze do danego elementu
- Na przejściu ścieżką skonfigurować odpowiednią akcję przeszukującą słowniki – oraz zapisującą wyniki do listy pozycji. Przykładowa konfiguracja zamieszczona poniżej:
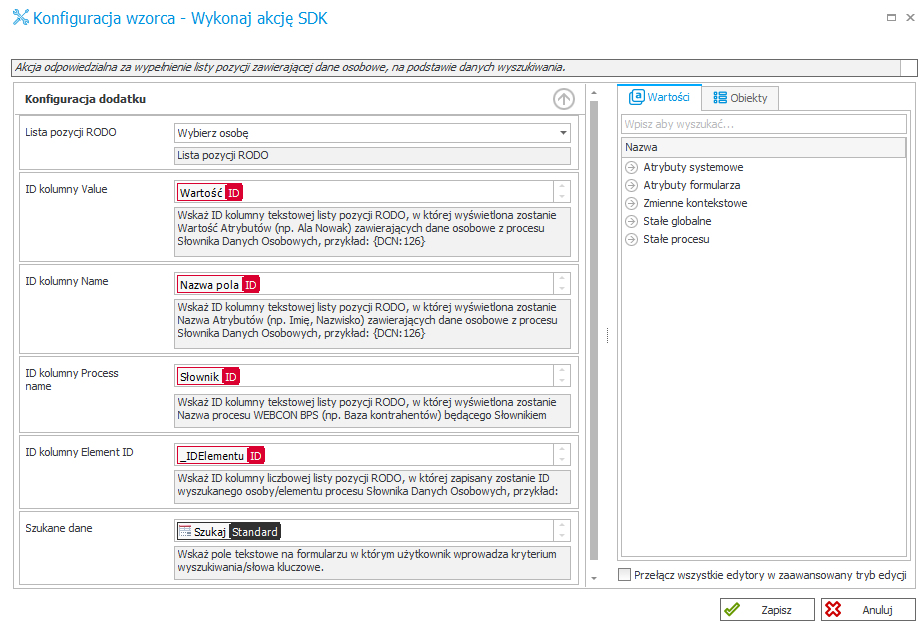
W trybie zaawansowanym można wychwycić różnicę w konfiguracji ID kolumn oraz Szukanych danych – jest to istotne z punktu przekazywania ID pól, do których ma być zapisany wynik, oraz dostarczanych informacji z formularza.
W przypadku, gdy chcielibyśmy przeszukać zewnętrzne źródła danych, należy skorzystać z akcji dedykowanej dla obsługi zewnętrznych źródeł danych. Różnicą w konfiguracji jest wskazanie źródła danych osobowych, które powinno być przeszukiwane oraz wykonanie mapowania:
- Nazwa
- Nazwa kolumny w źródle danych
- Wyszukiwanie
- Określa czy system powinien przeszukiwać po danej kolumnie ( szukać frazy)
- Widoczność
- Określa czy dana kolumna [nazwa] , będzie widoczna na liście pozycji z wynikami
- Jeśli kolumna była oznaczona jako false, ale jednocześnie następowało po niej wyszukiwanie – system pokaże wynik w liście pozycji
W dalszym etapie użytkownik powinien określić, które rekordy maja podlegać dalszej operacji.
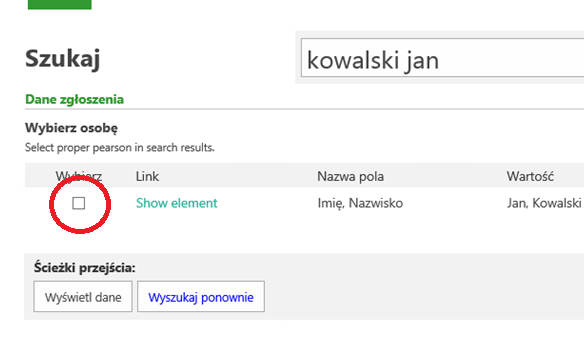
Wykonuje to poprzez zaznaczenie rekordu na liście pozycji (zaznaczając checkbox w odpowiednim wierszu). Z punktu widzenia BPS i dalszego procesowania – przepiszemy identyfikatory do pola nagłówkowego skąd BPS będzie pobierać Identyfikatory do dalszych czynności. Do przepisania, identyfikatorów wykorzystamy jedną z akcji dostępnych w SDK:

Rysunek 7. Akcja przepisująca wybrane Identyfikatory z listy pozycji do pola nagłówkowego
Logika działania akcji polega na pobraniu identyfikatorów ( _IDElementu) z listy pozycji ( Wybierz osobę) z zaznaczonych wierszy ( Wybierz) zgrupowaniu ich i przepisaniu do pola nagłówkowego (_Wybrana osoba) – wraz z separatorem ‘;’. W przypadku gdy wskażemy wiele wierszy uzyskamy wynik ID1;ID2;ID3; itd.
Kolejno – na formularzu można udostępnić raporty ( Tabela danych, zasilane Custom źródłami) prezentujące dwie grupy informacji:
- Dane ze słowników – prezentują dane, jakie występują w powiązaniu z danym identyfikatorem pochodzące ze słownika danych osobowych (sam słownik i filtry, konfigurujemy na poziomie atrybutu Tabela danych)

Konfiguracja – tej dokonujemy poprzez utworzenie atrybutu Tabela danych oraz zbudowanie filtra, w którym podamy identyfikator osoby, której dotyczy sam wniosek ( tu w przykładzie [_WybranaOsoba])

Rysunek 8. Konfiguracja atrybutu Tabela danych (SQL Grid) – Zebrane dane
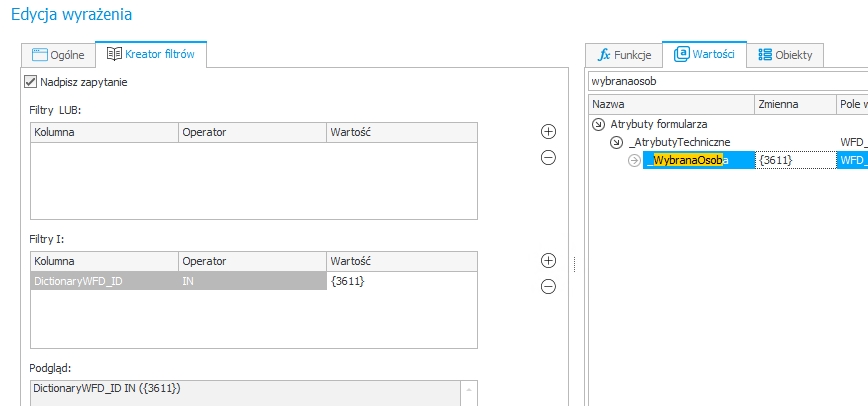
Rysunek 9. Konfiguracja filtrów na źródle danych
- Elementy w procesach powiązanych – prezentuje wystąpienia (WFD_ID) wraz z linkami do danego elementu, które posiadają zawarte w atrybutach identyfikatory osób.
Konfiguracja – Konfiguracja odbywa się w analogiczny sposób jak przy danych ze słowników – różnicą jest wykorzystanie Custom źródła wykorzystania danych osobowych.
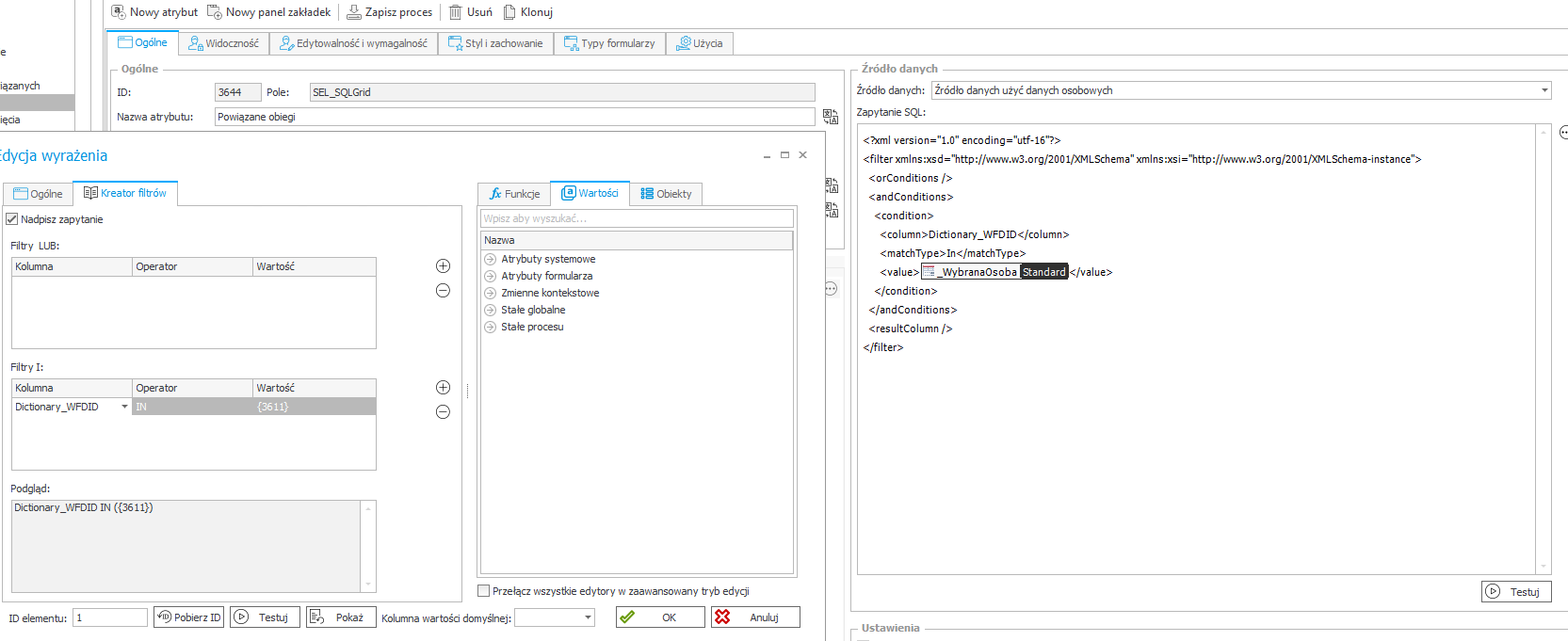
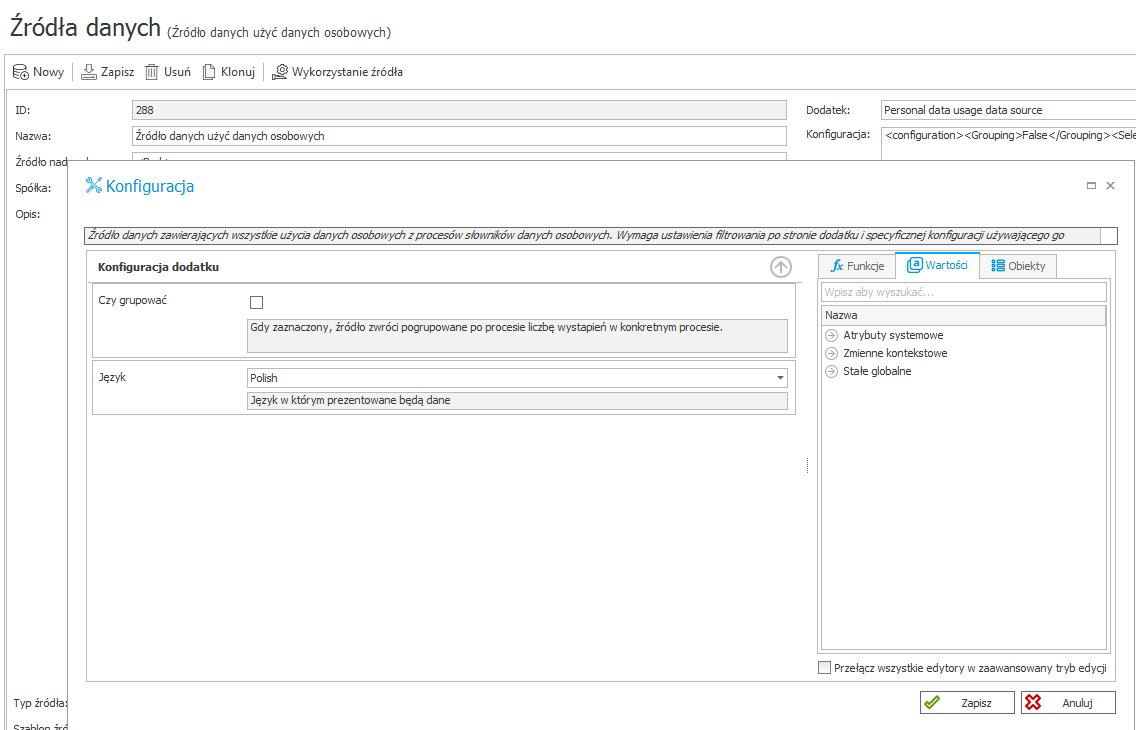
Rysunek 10. Konfiguracja custom źródła do prezentacji atrybutu Tabela danych (SQL Grid)

Rysunek 11. Tabela danych – prezentująca wystąpienia kluczy osób, w konkretnych instancjach w procesach
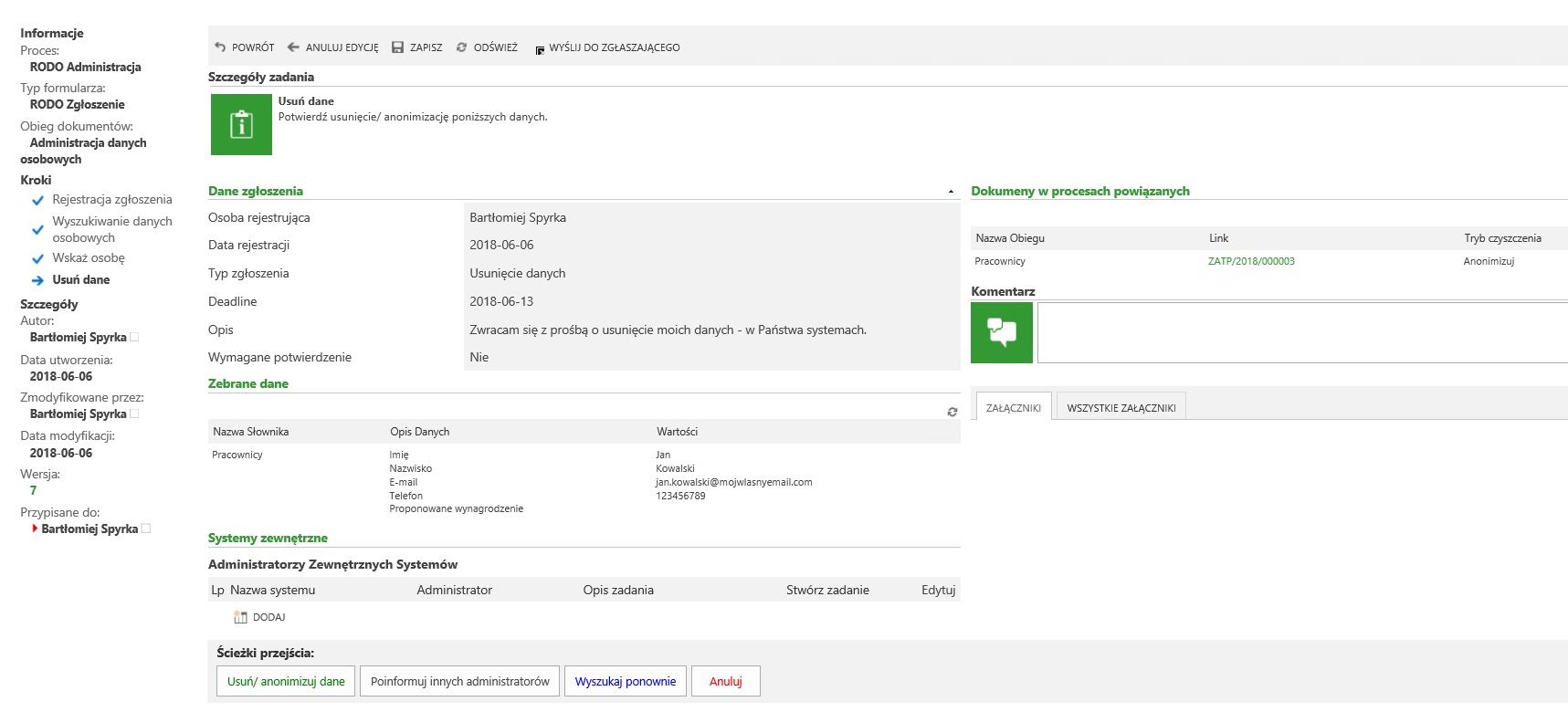
Rysunek 12. Widok formularza. po wyznaczeniu kluczy osób
Usuwanie danych osobowych:
Ostatnim elementem który zostanie wykorzystany jest akcja uruchamiająca operacje anonimizacji / usuwania danych z bazy BPS na której operujemy.
Należy skonfigurować akcję [Usuń dane osobowe] wskazując Identyfikator klucza osoby / osób ( po średniku).
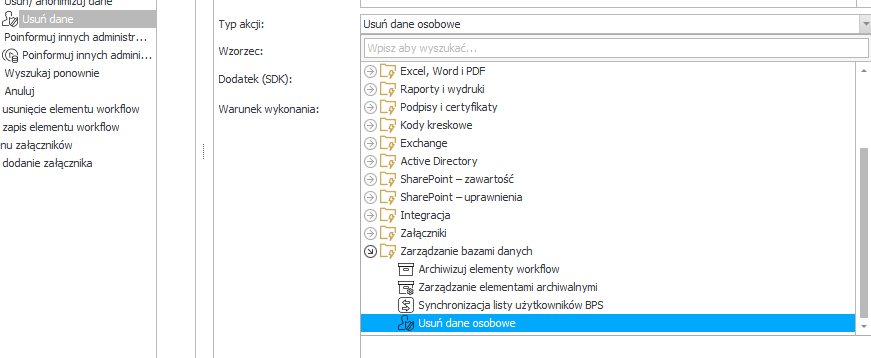
Akcja posiada tryby działania w podziale na źródła BPS ( procesy BPS) oraz źródła zewnętrzne:
- Konfiguracja dla obsłużenia źródeł opartych o proces BPS
- W konfiguracji wskazujemy jedynie atrybut zawierający klucze osób ( WFD_ID) które mają zostać odszukane we wszystkich procesach posiadającch przynajmniej jeden atrybut słownikowy, oznaczony jako dane wrażliwe / osobowe. Przykładowo:
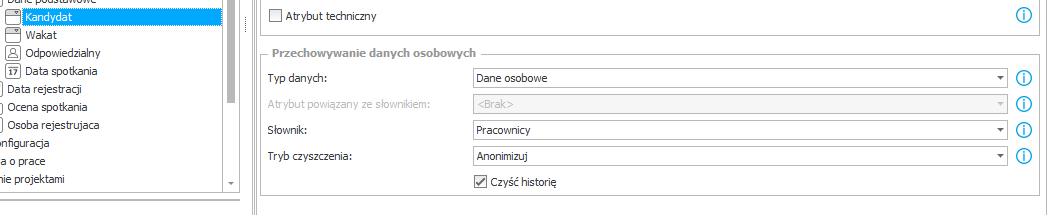
Rysunek 13. Oznaczenie atrybutu – zasileniem danymi osobowymi

Rysunek 14. Oznaczenie procesu jako słownika danych osobowych – oparty o BPS
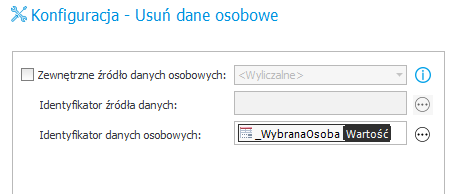
Rysunek 15. Przykład konfiguracji akcji usuwania danych osobowych w oparciu o źródła danych osobowych opartych o BPS
- Konfiguracja dla obsłużenia źródeł, które nie są oparte o proces BPS
- Wsparcie dla zewnętrznych źródeł dzieli się na dwa przypadki:
- Wskazanie statyczne źródła danych ( wybór z listy)
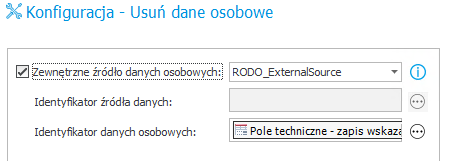
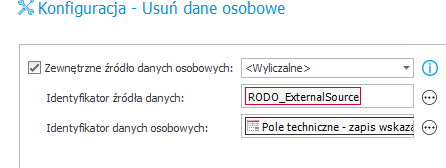
- Wskazanie dynamiczne ( z listy wybieramy <Wyliczalne> i w identyfikatorze wskazujemy ID źródła danych np. {DS.:174}) -rozwiązanie to pozwala zastosować jedną akcję na wiele źródeł danych i wykonać ją w pętli np. z zastosowaniem brancha.
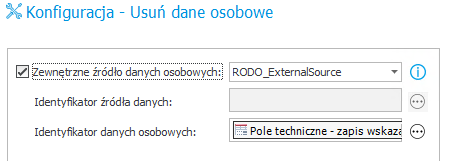
- Wskazanie statyczne źródła danych ( wybór z listy)
- Wsparcie dla zewnętrznych źródeł dzieli się na dwa przypadki:

3. Podsumowanie
Jak widać, konfiguracje samych akcji i źródeł danych nie są mocno skomplikowane dla osób na bieżąco wykorzystujących WEBCON BPS. Do całej konfiguracji należy dołożyć dodatkowy element w postaci identyfikacji źródeł danych osobowych występujących w systemie ( oparte o SQL, proces BPS, listy Sharepoint itd.) oraz oznaczenie atrybutów i kolumn list pozycji jako elementy przechowujące dane osobowe wraz z identyfikacją źródła ich pochodzenia. Dopiero wszystkie te elementy połączone w całość stanowić będą komplet pozwalający na zarządzanie danymi osobowymi w procesach WEBCON BPS.
Jak w SDK dla Collected personal data wstawić znak podziału nowej lini po każdej wartości?