Dotyczy wersji 2021.1.x autor: Dawid Golonka
Artykuł jest odświeżeniem już istniejącego artykułu -> Import-Eksport – Dobre praktyki tworzenia procesów
Wstęp
System WEBCON BPS posiada mechanizm pozwalający przenosić definicje procesów między kilkoma niezależnymi środowiskami. W pełni wspierany jest model środowisk DEV-TEST-PROD, w którym to modelu środowisko deweloperskie (DEV) przeznaczone jest do tworzenia nowych procesów, środowisko testowe (TEST) służy wykonywaniu testów funkcjonalnych przed ostatecznym wdrożeniem rozwiązania na środowisko produkcyjne (PROD) na którym pracują użytkownicy.
Tworzenie procesów w taki sposób, by były one niewrażliwe na kontekst środowiska w którym pracują, wymaga przestrzegania pewnego reżimu. Wynika on jednak naturalnie z funkcjonalności dostępnych w WEBCON BPS Studio oraz działania mechanizmów platformy. Dzięki właściwemu podejściu zastosowanemu przy projektowaniu procesów, możliwe będzie wykorzystanie mechanizmu Import-eksport do automatycznego i szybkiego przenoszenia zmian między środowiskami.
Przed przejściem do omawiania zasad jakimi należy się kierować tworząc eksportowalne obiegi, zamieszczono kilka słów wyjaśnienia dotyczących działania mechanizmu Import-eksport. Jego zrozumienie pozwoli łatwiej wyjaśnić konieczność stosowania opisywanego podejścia przy tworzeniu procesów.
Import-eksport od strony technicznej
Wszystkie elementy tworzonego procesu takie jak atrybuty, typy formularzy, obiegi czy źródła danych są w systemie jednoznacznie identyfikowalne przez ID.
Przykłady identyfikatorów różnych elementów procesu.
Obiegu:

Atrybutu:
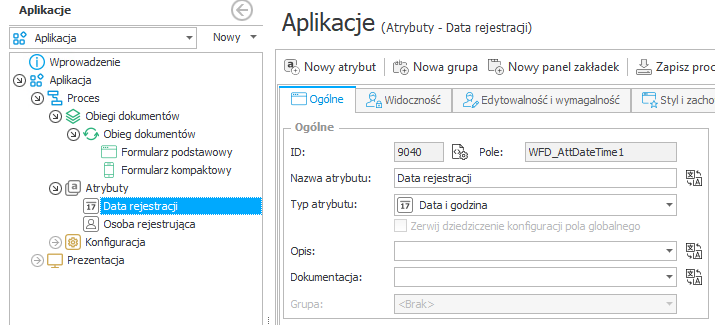
Kroku:

Identyfikatory są unikalne w skali środowiska (a dokładniej bazy danych) na którym zostały utworzone. Oznacza to, że identyczny proces utworzony na dwóch różnych środowiskach, będzie posiadał różne identyfikatory swoich obiektów (atrybutów, obiegów, dokumentów etc.).
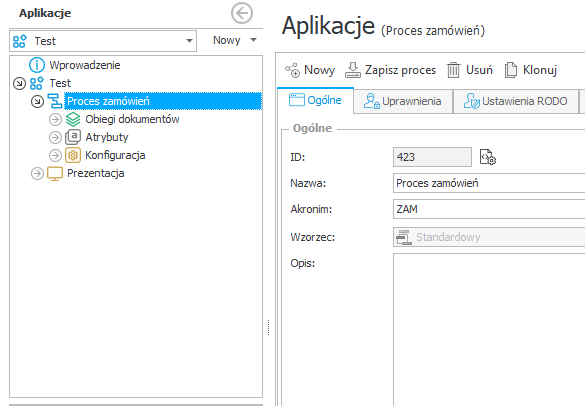
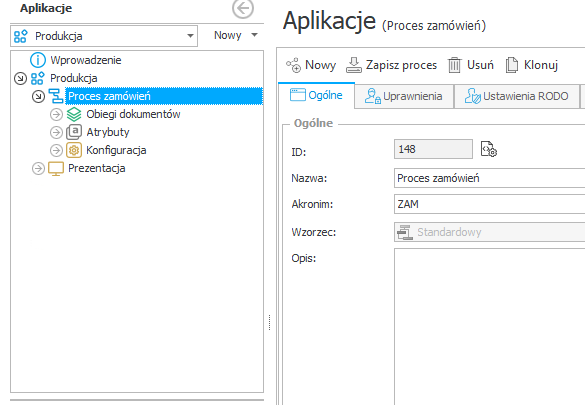
Przykładowy proces „Proces składania wniosku urlopowego” wdrożony na środowisku TEST oraz PROD – różne identyfikatory procesu.
| Środowisko TEST:
|
Środowisko PROD:
Mechanizm Import-eksport podczas przenoszenia procesu na inne środowisko musi być w stanie skojarzyć proces importowany z istniejącym na środowisku by rozpoznać, które elementy zostały zmienione, które zostały dodane, a które usunięte. By możliwe było jednoznaczne zidentyfikowanie wszystkich elementów procesu, mechanizm Import-eksport bazuje nie na ID (które jak wcześniej wspomniano jest różne na różnych środowiskach) ale na dedykowanym identyfikatorze GUID. Identyfikator GUID, podobnie jak ID, jest automatycznie nadawany elementom procesu podczas ich tworzenia. W przeciwieństwie jednak do identyfikatora ID, GUID pozostaje niezmienny w kontekście wielu środowisk. GUID zapisywany jest w bazie danych i przenoszony wraz z importowanym procesem na nowe środowiska. Dzięki temu technicznemu rozwiązaniu, mechanizm Import-eksport bazując na GUID, jest w stanie rozpoznawać wszelkie zmiany i poprawnie aktualizować proces. Aby sprawdzić, jaki GUID ma dany element systemu (Proces, Obieg) należy wybrać ikonę znajdującą się na prawo od identyfikatora:
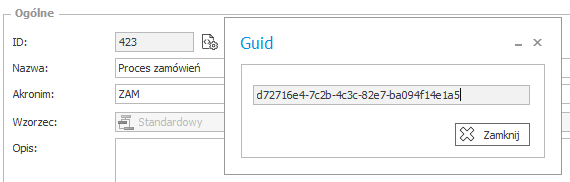
Uwaga:
Pracując w rygorze DEV-TEST-PROD, z wykorzystaniem mechanizmu Import-eksport do przenoszenia zmian z jednego środowiska na drugie, nie można dokonywać ręcznych zmian w procesie na środowisku PROD. Wynika to z tego, że dodany poza mechanizmem Import-eksport nowy element procesu na środowisku PROD, będzie posiadał inny identyfikator GUID co sprawi, że przy najbliższym imporcie tego procesu ze środowiska TEST wszelkie zmiany zostaną nadpisane (nowo utworzony element zostanie usunięty, ponieważ na środowisku TEST obiekt o takim GUID nie istnieje).
W przypadku sytuacji awaryjnej w której jakakolwiek modyfikacja procesu musiała zostać dokonana manualnie, poza mechanizmem Import-eksport, należy zadbać by wszystkie środowiska zostały po takiej zmianie poprawnie zsynchronizowane. Przez poprawną synchronizację należy rozumieć wyeksportowanie zmienionego procesu ze środowiska PROD, a następnie zaimportowaniu go na środowisko TEST oraz DEV.
Synchronizacja ręczna, czyli ręczne wykonywanie identycznych modyfikacji procesu na pozostałych środowiskach, nie jest poprawnym podejściem ponieważ nie gwarantuje spójności procesu w ramach środowisk DEV-TEST-PROD i może doprowadzić do błędów przy wykonywaniu importów w późniejszym czasie.
Podstawowe zasady tworzenia eksportowalnych procesów
W tej części omówione zostaną podstawowe zasady, którymi należy się kierować przy projektowaniu i tworzeniu procesów tak, by było możliwe ich wdrożenie na środowisko PROD, przy pomocy mechanizmu Import-eksport w sposób szybki i bezbłędny. Poniższe zalecenia są ważne nie tylko z powodu możliwości korzystania z Import-eksport – należy je stosować generalnie, jako dobre praktyki tworzenia procesów dzięki którym tworzone rozwiązania będą bardziej zrozumiałe, mniej wrażliwe na zmianę, a w konsekwencji bardziej niezawodne.
Używanie Tagów
Tagi są elementami używanymi przy tworzeniu wyrażeń (SQL, CAML, JavaScript), a także Reguł Biznesowych i Reguł Formularza. Tag reprezentuje konkretną wartość konkretnego obiektu w systemie np. wartość atrybutu formularza.
Tagi w przypadku SQL oraz CAML mają postać nawiasów klamrowych { i }
w przypadku JavaScript nawiasów klamrowych w połączeniu ze znakiem „hash” #{ i }#
Tagi zamieniane są na konkretne wartości w trakcie wykonywania wyrażenia.
Ponieważ tagi reprezentują obiekty których ID może się zmieniać po przeniesieniu procesu na inne środowisko, jest niezmiernie ważne by w tworzonych wyrażeniach (warunkach wykonania, zapytaniach) używać właśnie tagów zamiast liczb jako stałych identyfikatorów. Wówczas w importowanym procesie automatycznie zostaną one podmienione na poprawne z punktu widzenia środowiska identyfikatory obiektów.
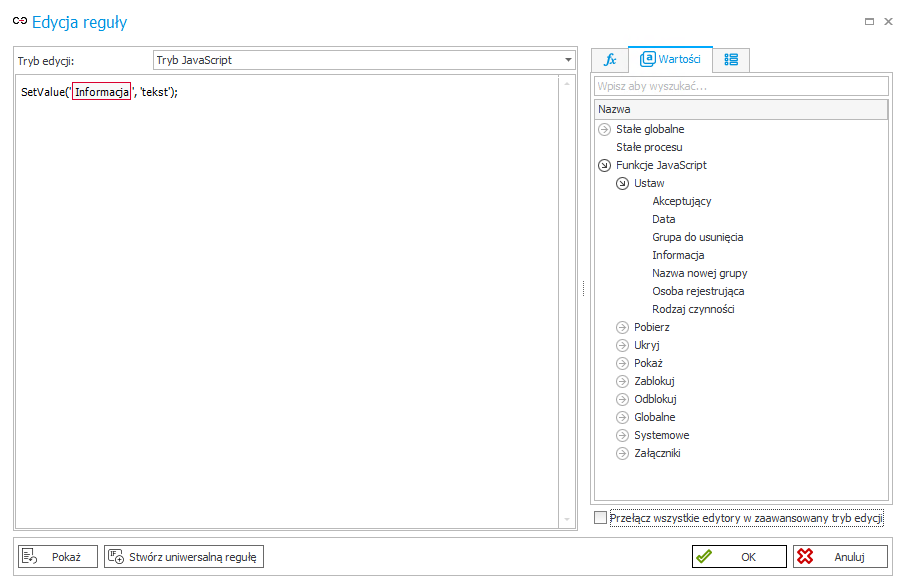
Poniżej przykład wyrażenia JavaScript ustawiającego wartość konkretnego atrybutu. Identyfikator atrybutu został zdefiniowany przy pomocy tagu.

To samo wyrażenie w trybie podstawowym edytora wyrażeń JavaScript.
Korzystanie ze stałych globalnych lub procesu w celu uniezależnienia się od środowiska
Różne środowiska z definicji będą różnić się od siebie pewnymi cechami. Najbardziej oczywistym jest to, że środowisko PROD będzie posiadać inny adres WWW niż środowisko TEST. Podobnych różnic wynikających z tego, że środowiska oparte są na innej infrastrukturze technicznej może być więcej.
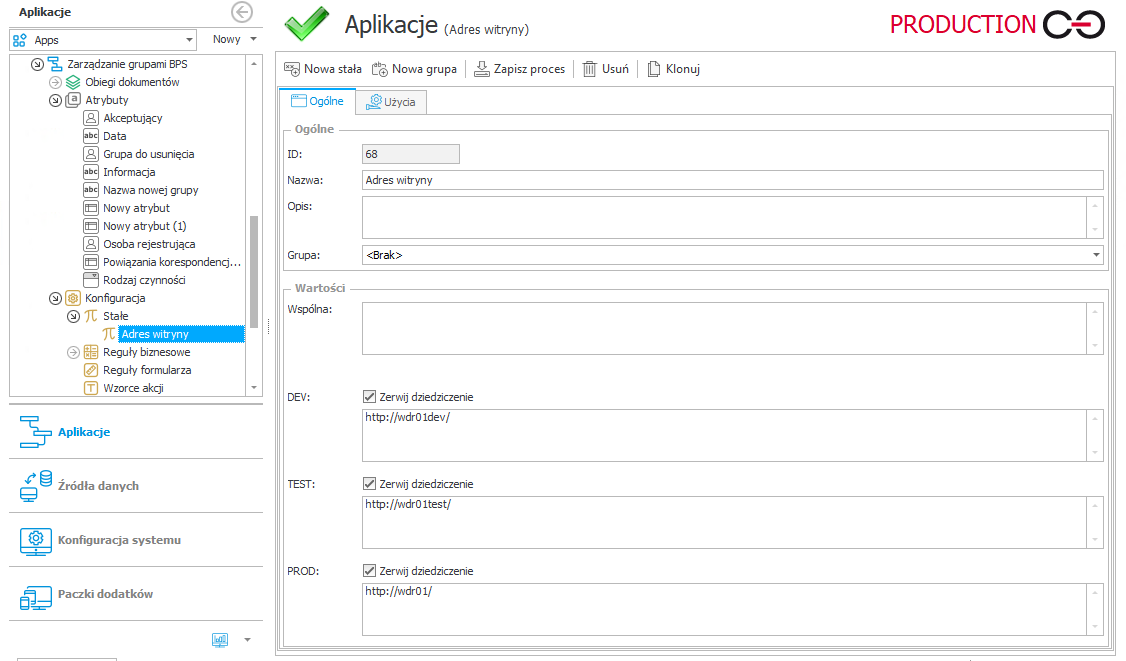
Jeśli wewnątrz procesu konieczne jest odwołanie się do wartości, która może być inna na różnych środowiskach, należy korzystać z funkcjonalności Stałych globalnych lub Stałych procesu.
Funkcjonalność Stałych globalnych pozwala zdefiniować różne wartości w zależności od środowiska na którym będzie uruchamiany proces. Wartości te użyte jako tagi przy tworzeniu wyrażeń wewnątrz procesu, zostaną podmienione na właściwe w zależności od środowiska.
Źródła danych w trybie DEV-TEST-PROD
Źródła danych są kolejnym elementem, który w naturalny sposób może różnić się w zależności od środowiska na którym jest definiowany. Różnica ta może wynikać z innego adresu źródła, innego użytkownika lub hasła dostępu do źródła.
Połączenia do źródeł danych definiowane w WEBCON BPS Studio pozwalają na podanie różnych parametrów w zależności od środowiska na którym mają pracować. Wykorzystanie tej funkcjonalności uniezależnia tworzony proces od kontekstu środowiska w którym będzie pracował.

Uwaga:
Źródła danych jako element definiowany poza procesem (proces korzysta ze źródła danych, niemniej źródło definiowane jest w konfiguracji systemu, nie w konfiguracji procesu) może być bezpiecznie modyfikowany po zaimportowaniu go na środowisko docelowe. Oznacza to, że tworząc proces na środowisku DEV, korzystający z zewnętrznego źródła danych nie jest wymagana znajomość adresu tego źródła na wszystkich środowiskach (TEST oraz PROD). Konfigurację źródła w kontekście właściwego środowiska można odłożyć do momentu wdrożenia procesu na to środowisko.
Korzystanie z bazodanowych nazw kolumn
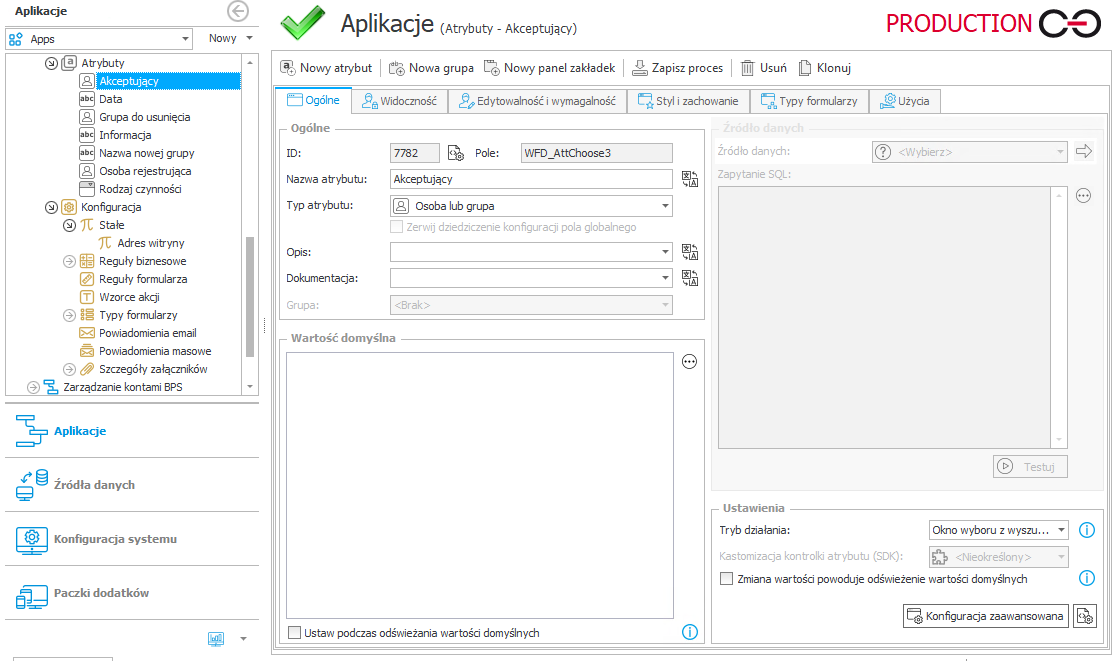
Wartości atrybutów procesu przechowywane są w bazie danych w kolumnie przydzielanej w momencie utworzenia atrybutu.
Przykład atrybutu „Akceptujący”, którego wartości przechowywane będą w kolumnie WFD_AttChoose3.
Eksportując a następnie importując proces na inne środowisko, mechanizm Import-eksport dba o to, by na nowym środowisku atrybut nadal był osadzony dokładnie w tej samej kolumnie bazy danych jak na środowisku z którego proces został wyeksportowany. Dzięki temu możliwe jest jednolite tworzenie zapytań, funkcji SQL lub procedur składowanych bazujących na nazwach kolumn bez konieczności ich modyfikowania w kontekście wielu środowisk.
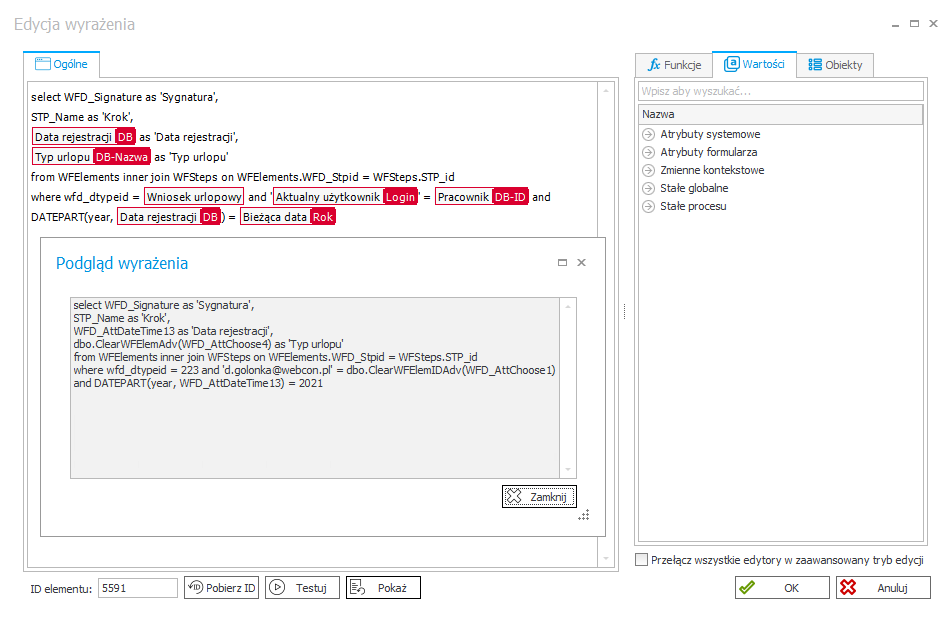
Poniżej przykład zapytania zwracającego sygnaturę dokumentu oraz datę rejestracji wniosku urlopowego. Taka konstrukcja zadziała poprawnie niezależnie od tego na jakim środowisku (DEV-TEST-PROD) zostanie uruchomiona.
Przykłady poprawnych i niepoprawnych konstrukcji
Poniżej przedstawionych zostało kilka konkretnych przykładów wyrażeń SQL w formie niepoprawnej z punktu widzenia funkcjonalności Import-eksport oraz możliwości ich przenoszenia między środowiskami. Zamieszczone zostało również wyjaśnienie, na czym polegają błędy, czym będą skutkować i jak powinny wyglądać prawidłowe wyrażenia.
a) Identyfikatory obiektów w wyrażeniach
Jak zostało wspomniane wcześniej – w konstrukcji wyrażeń należy unikać wpisywania identyfikatorów obiektów jako stałych liczb.
Poniżej przykład warunku wykonania akcji w zależności od typu dokumentu (Nieprawidłowo).
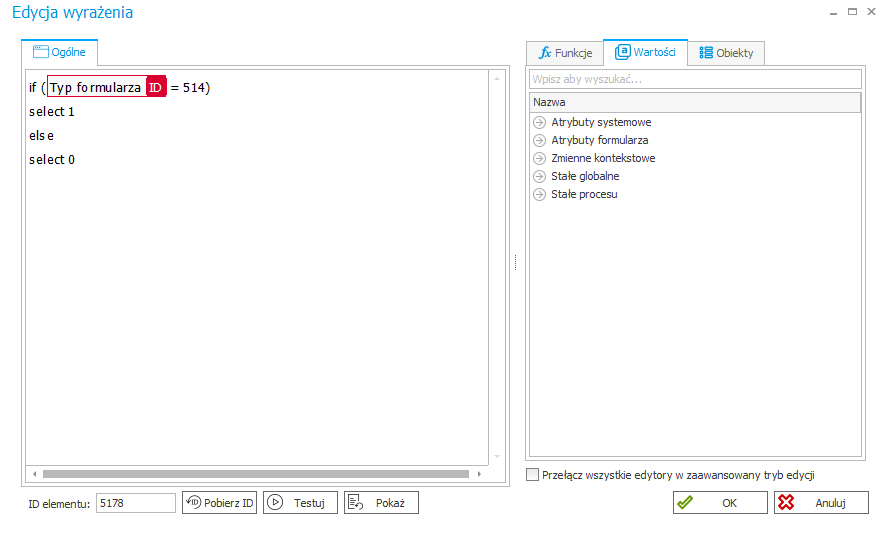
W przykładzie tym niepoprawnie została użyta wartość 514 określająca identyfikator typu dokumentu.
Identyfikator ten jest co prawda poprawny w kontekście środowiska DEV, lecz po zaimportowaniu procesu na środowisko PROD identyfikator typu dokumentu może być inny, a w konsekwencji cały warunek może nie zadziałać poprawnie.
Zamiast podawać wprost identyfikator obiektu należy użyć właściwego tagu, który zostanie prawidłowo podmieniony w momencie importowania procesu.
Wyrażenie po poprawieniu (Prawidłowo)
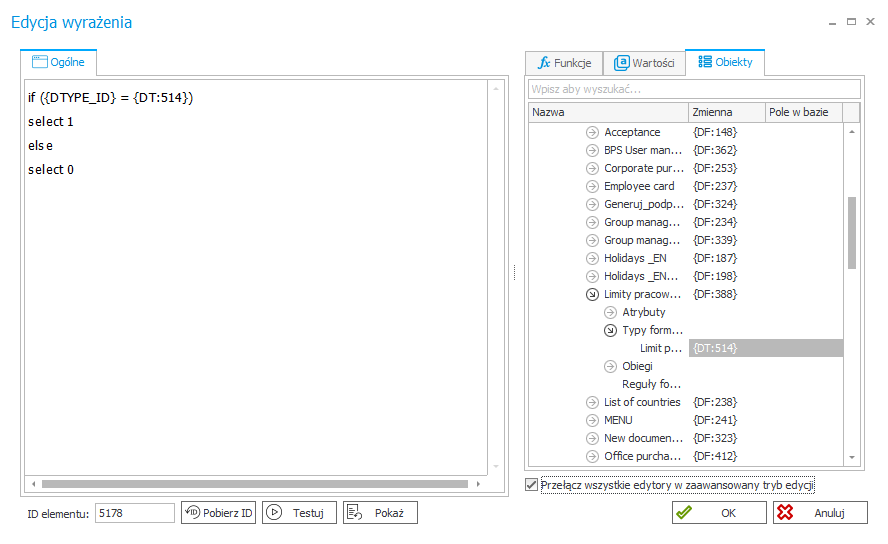
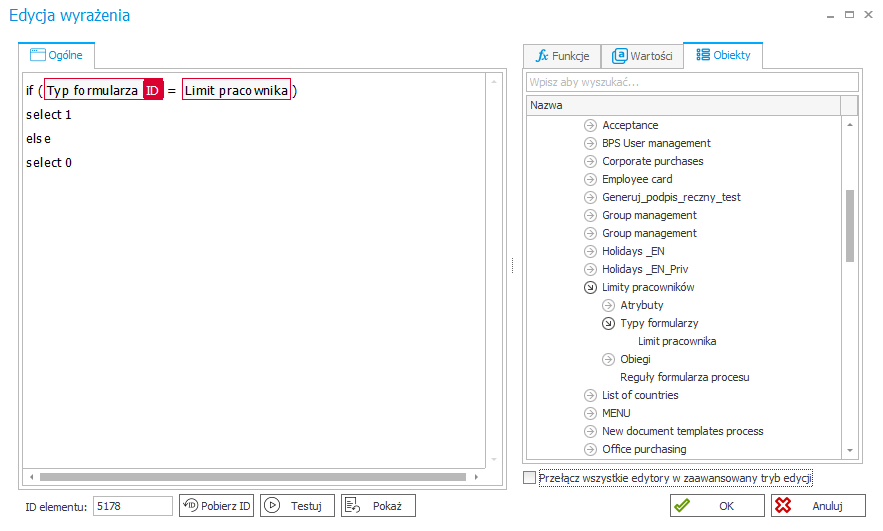
Oraz to samo wyrażenie w trybie podstawowym (Prawidłowo)
b) Grupa SharePoint jako stała globalna
Innym, bardziej złożonym przykładem jest wykorzystanie funkcji SQL sprawdzającej czy użytkownik o podanym loginie należy do danej grupy SharePoint.
Warunek taki może być użyty w celu określenia widoczności atrybutu (Nieprawidłowo).

W powyższym przykładzie niepoprawnie została użyta liczba 45 jako identyfikator grupy SharePoint oraz adres witryny w postaci ciągu znaków http://wdr01/. Obie te wartości będą inne na środowisku PROD co sprawi, że warunek będzie działał nieprawidłowo.
By uniezależnić powyższe wyrażenie od kontekstu środowiska na którym będzie wykonywane należy wykorzystać mechanizm Stałych globalnych.
W konfiguracji systemu tworzymy dwie stałe: „Adres witryny” oraz „Grupa SP administratorzy” w których definiujemy poprawne wartości, oddzielnie dla każdego środowiska.
Utworzonych stałych należy użyć jako tagów w wyrażeniu. Dodatkowo zamiast na sztywno wpisanego loginu użytkownika został użyty tag reprezentujący aktualnie zalogowanego użytkownika.
Wyrażenie (Prawidłowo):

Oraz to samo wyrażenie w trybie podstawowym (Prawidłowo)
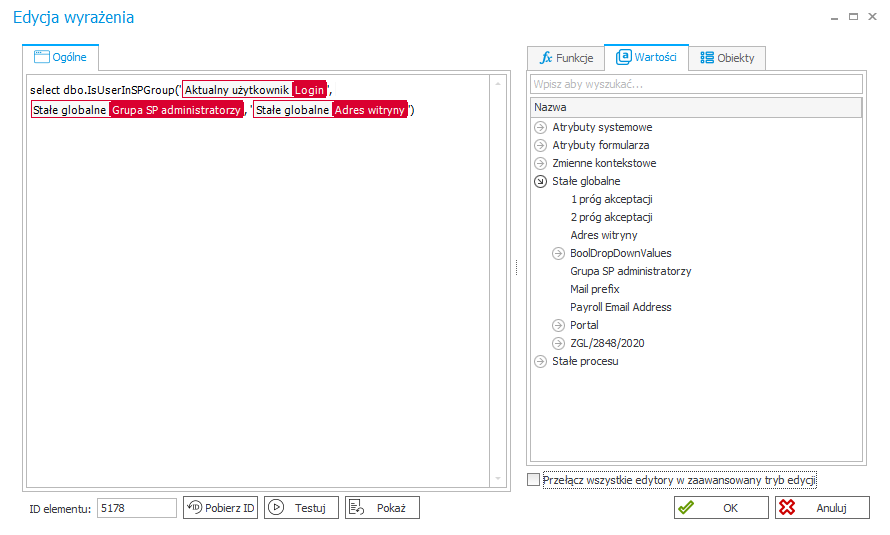
Tagi w momencie wykonywania wyrażenia zostaną zastąpione poprawną, z punktu widzenia środowiska na którym wyrażenie jest wykonywane, wartością.
c) Hiperłącze
Rozważmy przypadek w którym obieg „Korespondencja” ma dwa typy formularzy: Korespondencji przychodzącej i Korespondencji wychodzącej. Każdy typ formularza Korespondencji wychodzącej jest powiązany do jednego typu formularza Korespondencji przychodzącej. Na formularzu Korespondencji przychodzącej chcemy wyświetlić wszystkie elementy powiązane Korespondencji wychodzącej oraz dać możliwość przejścia do tych elementów za pomocą linka.
Do tego celu można użyć atrybutu typu „Tabela danych” w którym wyświetlone zostaną sygnatura, data rejestracji oraz data wysłania elementu powiązanego. Sygnatura będzie linkiem umożliwiającym przejście do danego elementu.
Przykładowe wyrażenie zwracające dane dla Tabeli Danych może wygadać w następujący sposób (Nieprawidłowo):
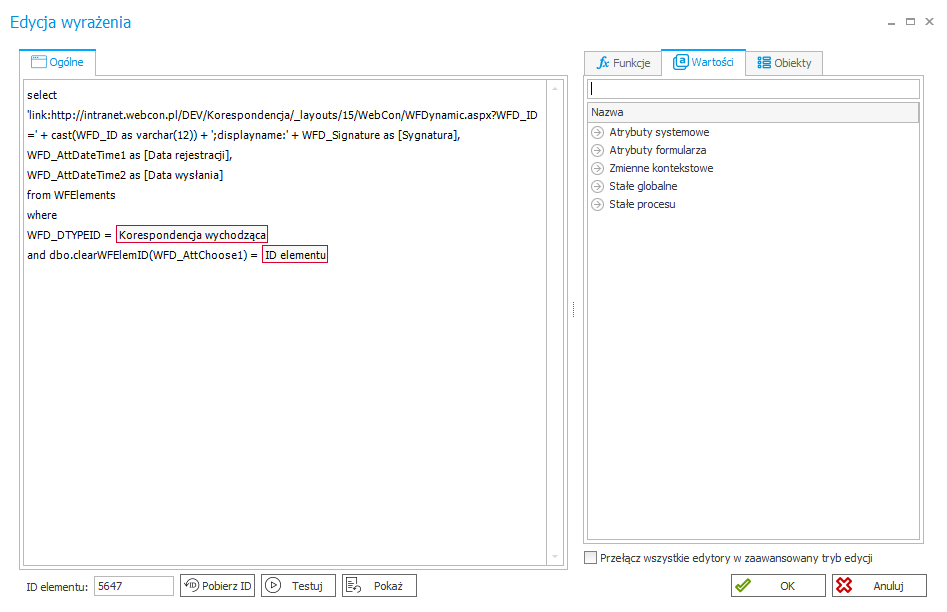
Rozwiązaniem jest utworzenie Stałej globalnej w której zdefiniowany zostanie właściwy adres witryny dla różnych środowisk. Stałej tej należy następnie użyć przy tworzeniu linka w wyrażeniu SQL (Prawidłowo).

W ten sposób wyrażenie na którym oparta jest lista SQL będzie niewrażliwe na kontekst środowiska na którym będzie wykonywane, co oznacza że funkcjonalnie będzie działało poprawnie na każdym ze środowisk.
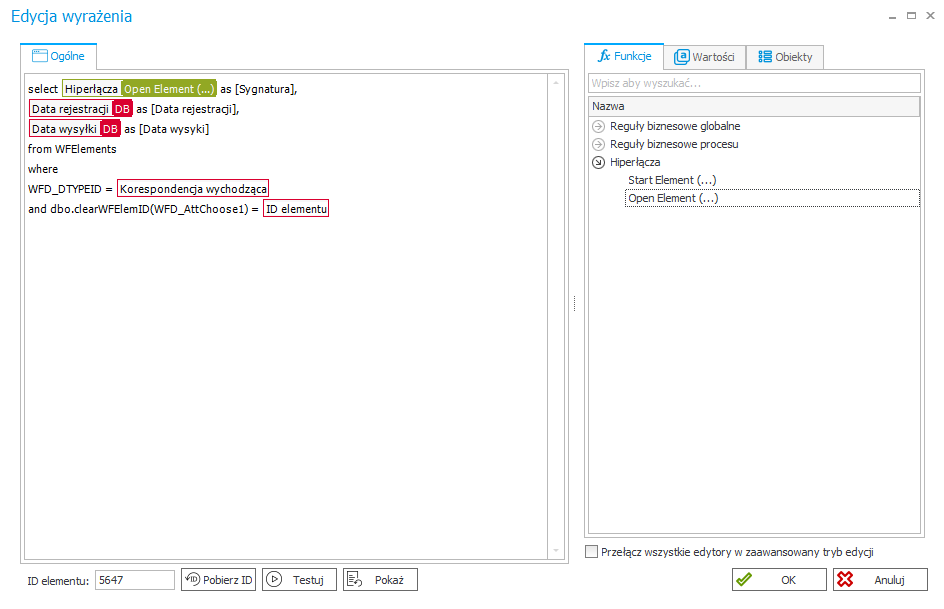
Pozostając w temacie generowania linków do elementów, warto wspomnieć, że do uzyskania podobnego efektu, można skorzystać również z wbudowanej funkcji „Open Element” dostępnej w zakładce „Funkcje” > „Hiperłącza”).
Więcej o funkcji można przeczytać tutaj: https://community.webcon.com/posts/post/the-hyperlink-action/65
Podsumowanie
Stosując się do praktyk opisanych w tym artykule, możliwe jest tworzenie takich procesów, które pozwolą uniknąć problemów, podczas przenoszenia ich między środowiskami.