dotyczy wersji: 8.3.x; autor: Anna Pilch
Na czym polega nauka?
Mechanizm nauki w OCR AI umożliwia tworzenie dedykowanych szablonów rozpoznawania dokumentów w procesie. W zależności od rodzaju przetwarzanych dokumentów wykorzystywane są różne wyróżniki, które jednoznacznie wskazują który szablon wykorzystać dla dokumentu. W procesie faktur najczęściej wykorzystywany jest NIP dostawcy. Jeżeli w procesie występują różne typy dokumentów najlepiej zbudować wyróżnik na podstawie NIPu oraz akronimu typu dokumenty. Dzięki temu dla każdego dostawcy oraz typu dokumentu może zostać utworzony osobny szablon (wzór) w jaki sposób mają być rozpoznawane wartości na dokumencie. Podczas procesu uczenia dla każdej wartości dla dokumentu wybierane są najbardziej prawdopodobne miejsca występowania oraz słowa kluczowe, które występują w pobliżu wartości.
Poniższy artykuł przedstawia proces nauki OCR. Pozostałe artykuły na temat OCR można znaleźć pod poniższymi linkami:
- Widok weryfikacji OCR dostępny dla formularza MODERN
- Nowy widok weryfikacji OCR
- Niestandardowe pola OCR
- OCR AI – instalacja
Jeżeli dla danego kontrahenta pierwszy raz uruchomiono proces nauki to tworzony jest nowy szablon dedykowany. Listę wszystkich szablonów znaleźć można na zakładce Konfiguracja systemu w WEBCON BPS Designer Studio.
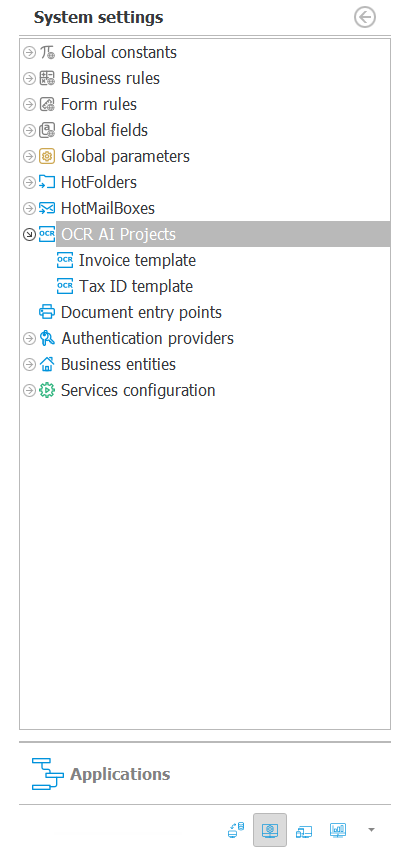
Jeżeli istniał już szablon dla kontrahenta to podczas nauki jest on douczany i powstaje kolejna wersja szablonu.
Jak stworzyć nowy szablon rozpoznawania dokumentów?
Proces tworzenia lub douczania szablonów OCR AI składa się z kilku etapów:
- Wybór elementów do nauki.
Użytkownik sprawdza poprawność rozpoznania wartości. Jeżeli jakaś wartość zostanie poprawiona można wskazać ją do procesu uczenia – wystarczy zaznaczyć check w kolumnie Nauka.
Wszystkie zaznaczone pola zostaną wykorzystane do korekty szablonu dla danego dostawcy.
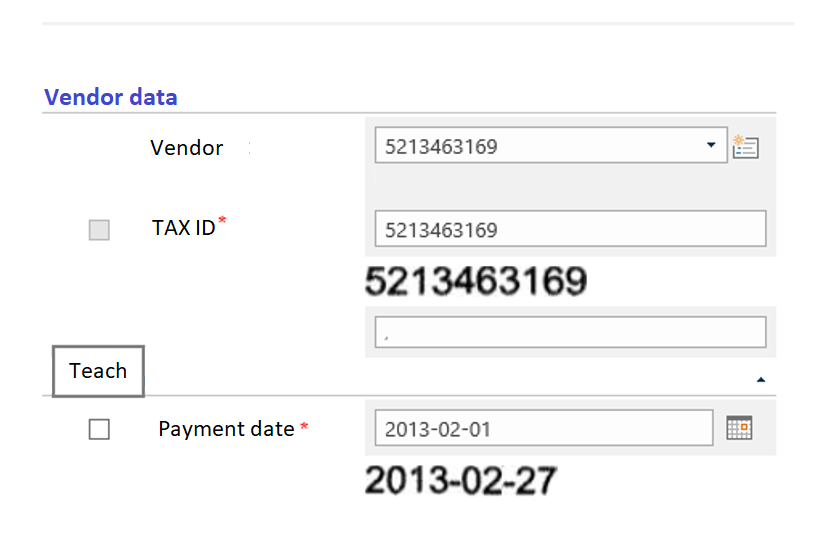
Jeżeli żadne pole nie zostanie wskazane do nauki – proces douczania sieci nie zostanie uruchomiony.
- Tworzenie nowego szablonu na podstawie istniejących dokumentów
W procesie nauki standardowo wykorzystane zostanie maksymalnie 100 ostatnich dokumentów, które:
- zostały zarejestrowane wcześniej niż bieżący dokument i są lub były w kroku weryfikacji,
- wystawione przez tego samego dostawcę (jeżeli wyróżnikiem jest NIP dostawcy),
- posiadają ten sam typ dokumentu w procesie, np. faktura kosztowa.
Jeżeli potrzebny jest inny niż domyślny dobór dokumentów do nauki (np. chcemy uczyć na podstawie 2 typów dokumentów lub tylko dokumentami, które wyszły z kroku Weryfikacji) można zmienić kryteria wyboru załączników za pomocą SQL w konfiguracji akcji Nauka OCR AI.

Ważne, aby w zapytaniu uwzględnić wyróżnik (jeżeli wykorzystujemy mechanizm sieci dedykowanych) oraz typ dokumentu (w przeciwnym razie zostaną wzięte wszystkie załączniki, które przeszły przez proces rozpoznania OCR AI).
Warto także wybrać kroki w których mamy pewność, że dokument został poprawnie zweryfikowany. Można w tym celu wykorzystać także pole techniczne, którego wartość będzie zmieniana w momencie zakończenia weryfikacji.
Tworzone obecnie szablony można zobaczyć na raporcie Kolejka uczenia OCR AI w WEBCON BPS Designer Studio.
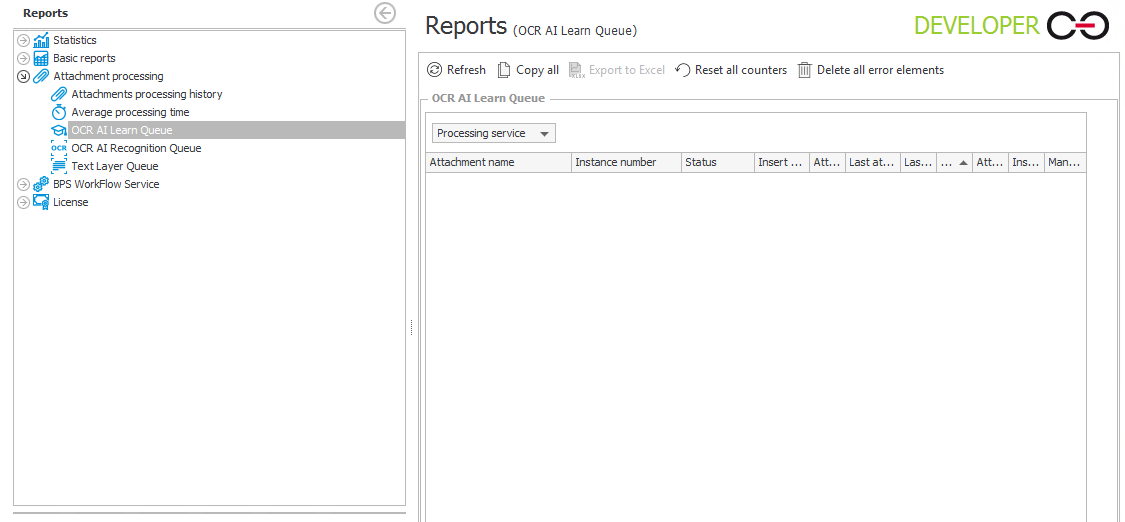
- Nowy szablon pokaże się w Projektach OCR AI na zakładce Konfiguracja systemu.
Klikając na szablon od wybranego dostawcy widać, która wersja szablonu została utworzona.
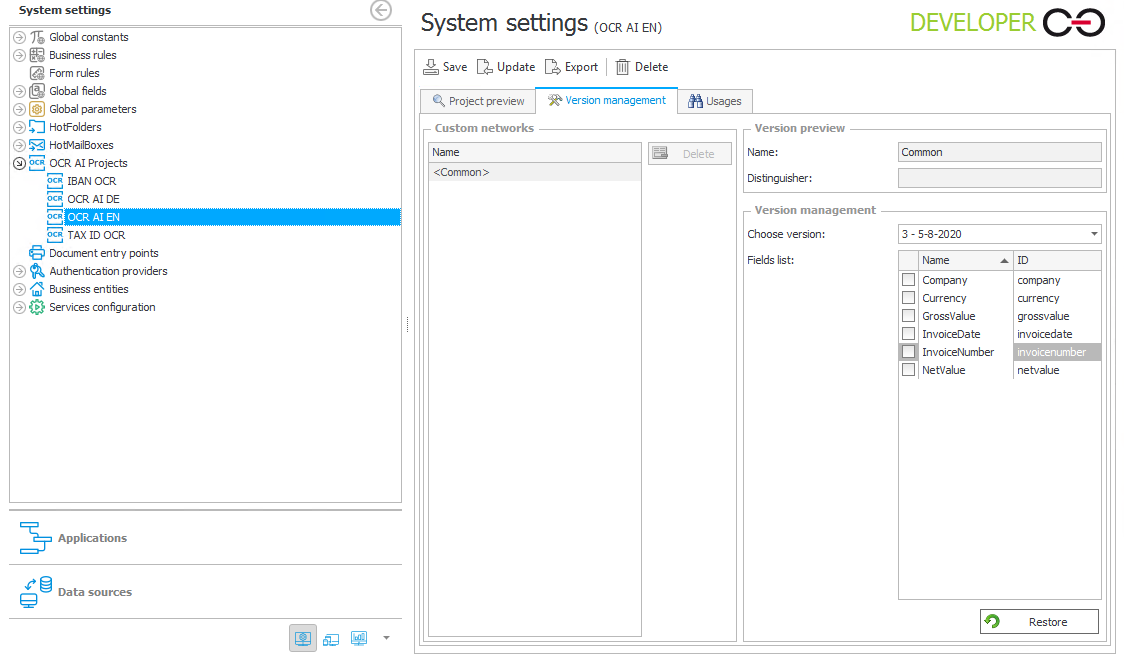
Od momentu pojawienia się nowego szablonu będzie on wykorzystywany podczas rozpoznania nowych dokumentów.
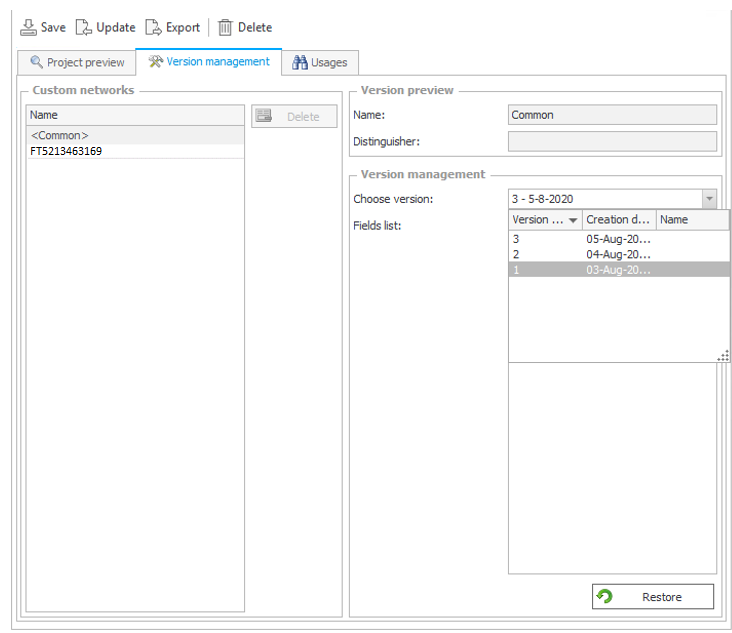
W razie potrzeby powrotu do wcześniejszej wersji danego pola należy:
– zaznaczyć pola do poprawy,
– wybrać wersję, którą chcemy przywrócić,
– potwierdzić przywrócenie przyciskiem Przywróć.
Na co zwracać uwagę przy uczeniu?
- Jakość skanu (warstwy tekstowej) – skan dokumentu musi być czytelny i posiadać poprawnie utworzoną warstwę tekstową. Jakość warstwy tekstowej można zweryfikować poprzez sprawdzenie w jaki sposób utworzone zostały „bloki” wokół tekstu. Jeżeli poprawnie wskazują one na pojedyncze wartości i możliwe jest ich skopiowanie do pól na formularzu to warstwa tekstowa została utworzona poprawnie. Jeżeli wartości wewnątrz bloków są posklejane lub bloki są nierówne wówczas dokument nie nadaje się do uczenia.
![]()
Powyżej widać że ze względu na złą jakość oraz nierówny skan blok został źle utworzony. Nie należy zatem wykorzystywać tego dokumentu do nauki.
- Dokument musi być w całości w wersji elektronicznej. Pismo ręczne uniemożliwia na poprawne stworzenie warstwy tekstowej.
- Ilość przykładów dokumentów – proces nauki najlepiej wykonywać w momencie gdy w bazie istnieje już kilka poprawnie zweryfikowanych dokumentów od danego dostawcy.
Stworzony szablon uwzględni wówczas drobne różnice pomiędzy dokumentami danego dostawcy. Jeżeli szablon tworzony będzie na pojedynczym przykładzie to będzie mniej elastyczny na zmiany na fakturze.
- Poprawne rozpoznanie szukanej wartości – warto wykorzystać mechanizm douczania tylko jeżeli szukana wartość występuje w dokumencie i poprawnie kopiuje się do pola na formularzu. Jeżeli pojedyncze znaki danej wartości są nieprawidłowe (np. zamiast 8 wstawione zostało B lub 0 zamiast O) nie należy wykorzystywać jej w procesie uczenia. Szablony OCR AI wykorzystywane są do wskazania poprawnego miejsca gdzie znajduje się wartość, nie mają one wpływu na jej format.
Przykład:
Jeżeli podczas rozpoznania wskazane zostało odpowiednie miejsce, ale po skopiowaniu znaki są złe – nie należy douczać szablonu. Złe znaki są wynikiem złej jakości skanu lub nietypowej czcionki.

- Dokładna weryfikacja wcześniejszych dokumentów – do procesu nauki OCR AI wykorzystywane są wszystkie dokumenty od danego dostawcy (z tym samym wyróżnikiem), które zostały zarejestrowane wcześniej niż bieżący dokument. Jeżeli nie zostały one zweryfikowane lub zostały wskazane błędne pola to uczenie może pogorszyć jakość rozpoznawania pól.
Na przykład patrząc na poniższą fakturę.
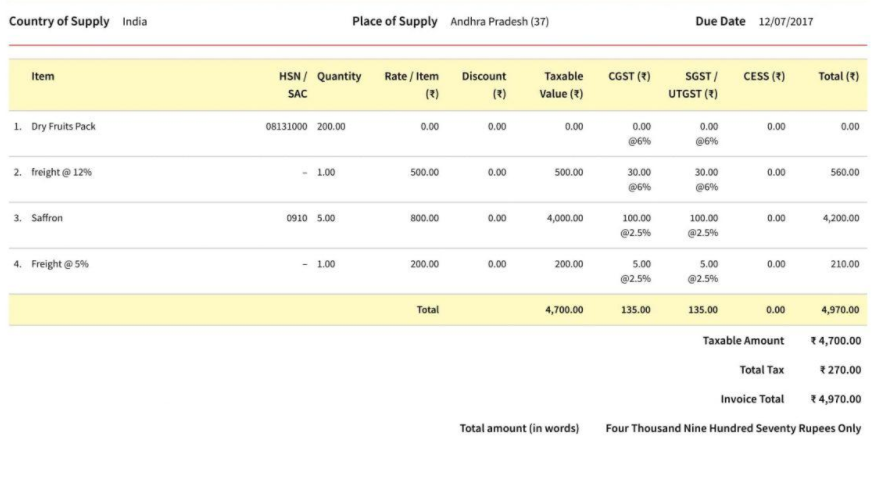
Jeżeli na pierwszych 10 fakturach kwota brutto została wpisana na podstawie wartości KWOTA NALEŻNOŚCI. To pomimo wprowadzenia poprawki na 11 fakturze i wskazania kwoty brutto z wiersza RAZEM PLN szablon będzie w dalszym ciągu pobierał wartość z pola KWOTA NALEŻNOŚCI.
W procesie nauki wykorzystanie zostanie 10 błędnych zweryfikowanych faktur i tylko jedna poprawna. Dlatego kluczowa jest dokładna weryfikacja wszystkich dokumentów.
Miejsce rozpoznania wartości zostanie skorygowane w momencie gdy liczba poprawnie zweryfikowanych dokumentów w bazie będzie znacząco większa niż liczba błędnych.
- Poprawny format szukanej wartości – szukana wartość musi być w prawidłowym formacie na dokumencie, w przeciwnym razie nie ma sensu douczanie.
Na przykład jeżeli data płatności została wpisana jako:

to nie będzie możliwe jej skopiowanie do pola daty na formularzu, a tym samym nie ma sensu uczenie na jej podstawie.
Podobnie jeżeli wartości są nieprawidłowo sformatowane na dokumencie. Przykładowo w poniższym przykładzie data jest napisana łącznie z oznaczeniem roku, dlatego kopiuje się zarówno data, jak i „r” (pole Opis), co uniemożliwia wprowadzenie tej wartości do pola typu data.

- Pieczątki/podpisy/ kody kreskowe – jeżeli na dokumencie w pobliżu szukanych wartości znajduje się pieczątka lub odręczny podpis może to uniemożliwić poprawne rozpoznanie tekstu w tej okolicy. Podobnie naklejony kod kreskowy, jeżeli nachodzi na tekst może zepsuć jakość rozpoznania.
![]()
Powyżej, nachodząca pieczątka spowodowała utworzenie złej warstwy tekstowej.
- Źródła danych/słowniki – jeżeli przy rozpoznawaniu wykorzystywane jest źródło danych to należy sprawdzić czy szukana wartość znajduje się w źródle. Jeżeli danej wartości nie ma to należy wprowadzić ją do źródła danych, nie ma sensu douczać dokumentu.
- Alfabet/język użyty na dokumencie – jeżeli na dokumencie użyty jest więcej niż jeden język/alfabet może to utrudnić prawidłowe rozpoznanie wartości na dokumencie.
- Częstość wykorzystania nauki – podczas uczenia wykorzystywane są wszystkie dokumenty od danego dostawcy, jeżeli nauka będzie wykonywana po każdym nowym dokumencie to wielokrotnie będziemy uczyć na podstawie tych samych danych. Wydłuży to czas oczekiwania na rezultaty uczenia. Dlatego zalecane jest aby weryfikować każdy dokument, natomiast proces nauki wywoływać w momencie gdy istnieje już kilka zweryfikowanych dokumentów od danego dostawcy.
Dzień dobry,
OCR nie odczytuje warstwy tekstowej na załącznikach podpisanych – wyłapuję takie dokumenty posługując się akcją 'Weryfikuj podpis załącznika' i przekazuję je do innego kroku. Czy jest natomiast jakaś możliwość do podobnej obsługi dla załączników PDF, które są zabezpieczone hasłem? Takie również przychodzą drogą mailową od kontrahentów.
Pozdrawiam!
Dzień dobry,
Niestety nie da się, załączniki zabezpieczone hasłem nie są w ogóle przetwarzane – od razu wyświetlany jest błąd.
Witam,
Na fakturach zamiast dat, zaczytuje się błędnie pole z faktury z numerem PKWiU, po wskazaniu poprawnych wartości i przejściu ścieżką douczającą, dalej występuje ten błąd. Kilkadziesiąt faktur zostało tak poprawionych, jednak gdy wpadają nowe, sytuacja się powtarza, czy jest jakiś sposób na rozwiązanie takiego problemu?
Pozdrawiam
Dzień dobry,
czy prawidłowe daty są w poprawnym formacie? Jak Państwo je zaznaczają w kroku Weryfikacji to przenoszą się bez problemu czy musza Państwo coś korygować?
Czy te daty pochodzą ze standardowego szablonu (data płatności, data wystawienia, data sprzedaży) czy są to jakieś pola dedykowane w tym projekcie OCR?
Pozdrawiam,
Pola są standardowe, po wybraniu poprawnych, system od razu poprawnie je wpisuje.
Dzień dobry
Czy mechanizm pozwala na rozpoznawanie faktur w innych językach niż polski? Jeżeli tak, to jakie języki i alfabety są obsługiwane? (np. cyrylica, greka).
Dzień dobry,
Rozpoznawane są wszystkie języki wspierane przez FineReader Engine 11
https://abbyy.technology/en:products:fre:win:v11:languages
Niektóre wymagają dodatkowej licencji