dotyczy wersji: 8.1.x; autor: Marcin Wiktor
1. Wstęp – czym są tagi i jak ich używać
Projektując obieg, często zachodzi potrzeba odwołania się do np. wartości z konkretnego atrybutu, porównania dat, sprawdzenia liczb czy dostępu do takich danych jak ID dokumentu, jego sygnatura czy typ dokumentu. Zamiast tworzyć skomplikowane zapytania do bazy, można w tym celu wykorzystać Tagi (zwane również roboczo wąsami).
Tagi w BPS są to wyrażenia ograniczone nawiasami klamrowymi – { i }, które są używane w polach umożliwiających wpisanie zapytania SQL takich jak np. wartość domyślna atrybutu, zapytanie ograniczające widoczność atrybutu, warunek wykonania akcji czy chociażby zapytanie ograniczające widoczność danej ścieżki przejścia. Ponadto tagów można używać w wielu innych miejscach jak np. definicja sygnatury, szablon wiadomości email czy komunikaty związane z akcjami typu „Przycisk w menu”.
W zapytaniu, w którym chcemy wykorzystać tagi, możemy albo wpisać je ręcznie, jeżeli znamy nazwę tagu, albo skorzystać z pomocy kreatora wyrażeń, który zawiera listę wszystkich tagów, których możemy użyć w danym miejscu. Lista dostępnych tagów zawsze jest generowana w kontekście miejsca, w którym uruchamiamy kreator wyrażeń więc nie ma obaw, że użyjemy tagu, który w danym miejscu nie będzie obsługiwany.
Przykładowo – tagi związane z automatyczną numeracją sygnatury będą wyświetlane tylko w miejscach, gdzie definiujemy sygnaturę obiegu/typu dokumentów.
Żeby zobaczyć, jakie tagi są dostępne w kontekście miejsca, gdzie chcemy je użyć, należy wejść do kreatora wyrażeń, klikając przycisk „Edytuj” pod interesującym nas polem. W tym przykładzie będzie to pole do określenia wartości domyślnej atrybutu.
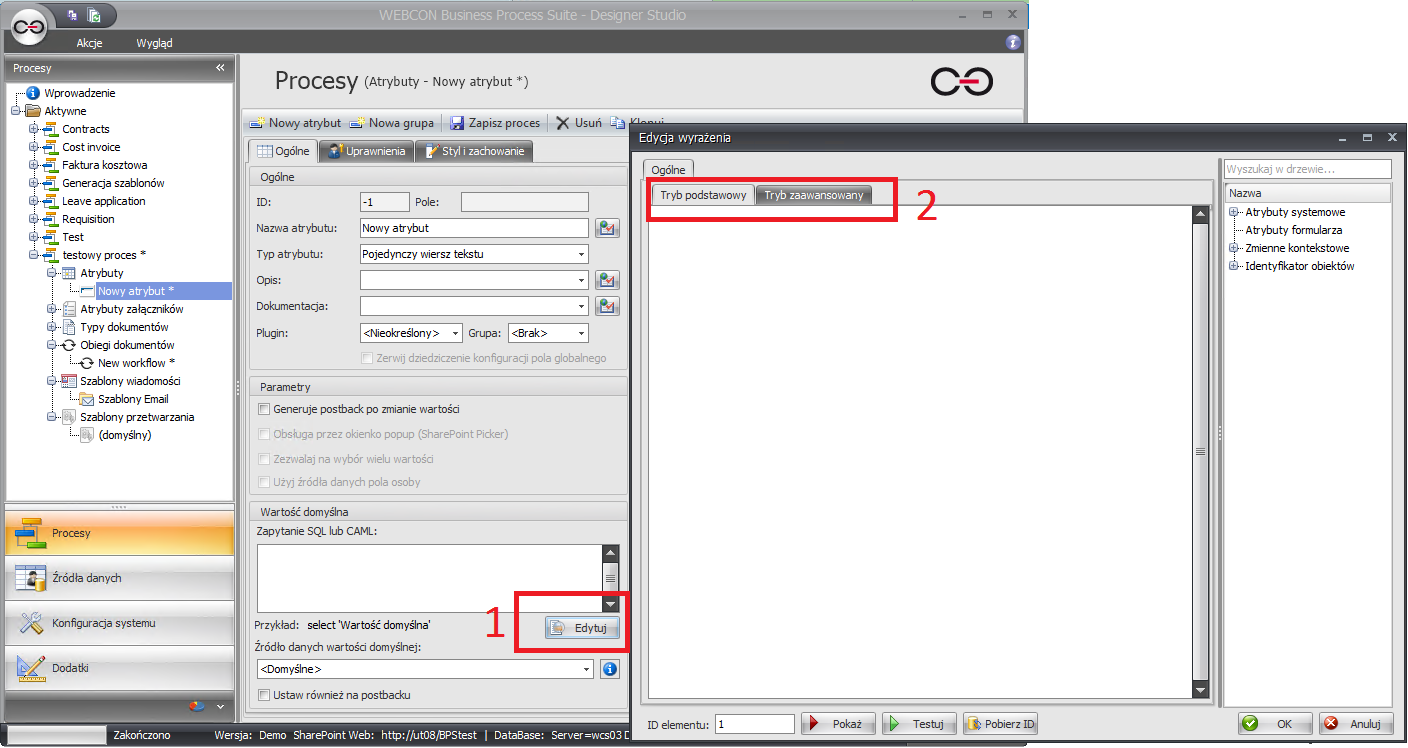
Domyślnie kreator wyrażeń jest zawsze otwierany w trybie podstawowym, w którym tagi użyte w wyrażeniu, wyświetlane są w przyjaznej dla użytkownika formie, mówiącej dokładnie, na jaką wartość, tag ten jest zamieniany. Tagi w treści wyrażenia możemy umieszczać przez dwukrotne kliknięcie na nie w drzewie po prawej stronie (tag zostaje wstawiony w miejscu kursora) albo przeciągnąć go w dowolne miejsce w treści wyrażenia.
Można też wpisać nazwę tagu ręcznie, co jest łatwiejsze w trybie zaawansowanym gdyż w menu po prawej stronie widzimy od razu nazwy tagów dla wszystkich elementów. W trybie zaawansowanym dodatkowo, w treści zapytania tagi nie są zamieniane na odpowiadające im wartości tylko są wyświetlane w formie tekstowej.
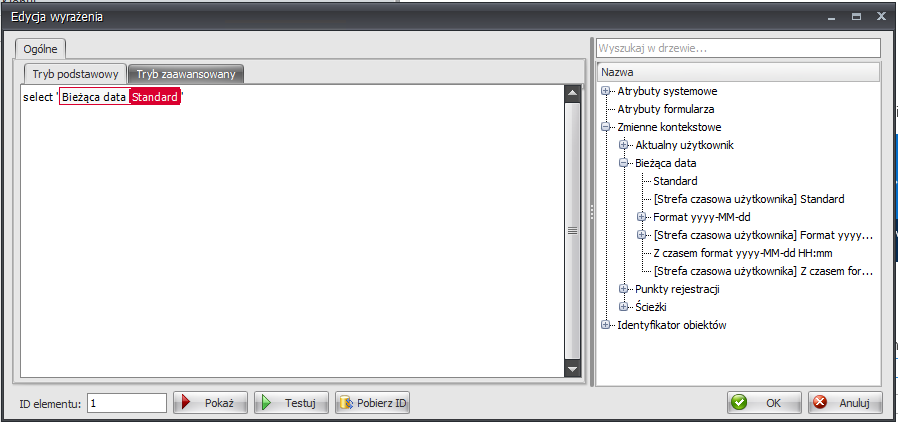
Po wejściu w tryb zaawansowany, tagi są wyświetlane w tekstowej formie oraz w menu po prawej stronie pojawiają się nowe kolumny – „Tag” oraz „Pole w bazie”
Kolumna „Tag” to nic innego jak po prostu tekstowa nazwa tagu. Kolumna „Pole w bazie” dotyczy części „Atrybuty formularza” oraz listy atrybutów dla danego procesu w grupie „Identyfikator obiektów”. Kolumna ta, wyświetla nazwę kolumny w tabeli WFElements, w której przechowywana jest wartość danego atrybutu.
Kolejną ciekawą funkcją w kreatorze wyrażeń jest znajdująca się w prawym górnym rogu wyszukiwarka. W trybie podstawowym umożliwia wyszukiwanie po nazwie elementów (np. bieżąca data lub nazwa poszukiwanego atrybutu) a w trybie zaawansowanym dodatkowo także po nowo wyświetlanych kolumnach – „Tag” i „Pole w bazie”.
Ostatnią funkcją kreatora wyrażeń jest podgląd treści zapytania lub jego rezultatu w kontekście wskazanego dokumentu. W tym celu w polu „ID elementu” znajdującym się na dole kreatora, wpisujemy ID dokumentu, dla którego chcemy zobaczyć treść wykonywanego zapytania lub jego rezultat.
Dostępne mamy 3 przyciski:
- Pokaż – wyświetla treść zapytania, jakie jest wykonywane dla dokumentu o podanym ID po podmienieniu tagów na odpowiednie wartości.
- Testuj – próbuje wykonać zapytanie po podmienieniu tagów na wartości ze wskazanego dokumentu. Prościej mówiąc, próbuje wykonać zapytanie, które mogliśmy podglądnąć po wciśnięciu przycisku „Pokaż”.
- Pobierz ID – pobiera ID ostatniego utworzonego dokumentu w procesie, w którym obecnie działamy i umieszcza je w polu „ID elementu”.
2. Konstrukcja tagów oraz grupy „Atrybuty formularza” i „Identyfikator obiektów”
Wśród tagów możemy wyróżnić 2 ich rodzaje – te, których nazwy są niezmienne dla wszystkich procesów i dynamicznie generowane, czyli grupy „Atrybuty formularza” oraz „Identyfikator obiektów”.
Tagi stałe mają z góry narzuconą nazwę, która jest zamieniana na konkretną wartość. Przykładowo tag {STP_NAME} zawsze zostanie zamieniony na nazwę kroku, w którym obecnie znajduje się dokument a {COM_NAME} zawsze zwróci nazwę wybranej spółki, dla której rejestrowany jest dokument. Więcej o tych dwóch grupach tagów można przeczytać w następnym rozdziale.
Inaczej ma się sprawa z tagami, które dotyczą atrybutów formularza oraz będących identyfikatorami obiektów. Dla każdego procesu mamy zupełnie inne atrybuty więc elementy, dla których można użyć tagów także zawsze będą różne. Dla atrybutów, tagi zawsze są tworzone według schematu {ID Atrybutu}. Jaki numer ID ma każdy atrybutów, możemy zobaczyć w ich konfiguracji, na zakładce „Ogólne”.
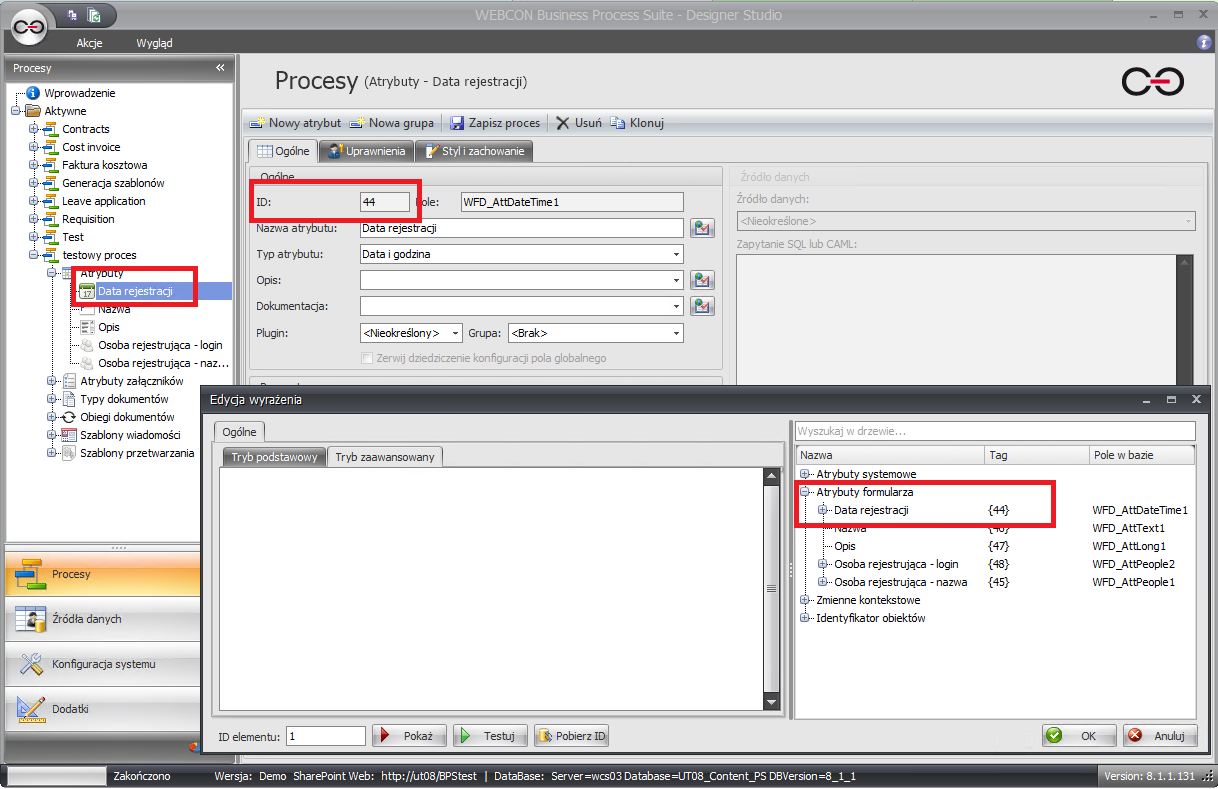
Zamiast w treści tagu podawać ID pola, można też podać odpowiadającą mu nazwę pola w bazie, np. {WFD_AttDateTime1}. Wartość, na jaką ten tag zostanie zamieniony, jest taka sama jak przy użyciu {44}. Jest to po prostu inny sposób zapisu.
W przypadku niektórych typów atrybutów, mamy możliwość dodatkowego formatowania wyświetlanej wartości. Dla pól, które w bazie są zapisane w formie ID#Nazwa możemy zdefiniować czy chcemy wyświetlać ID, nazwę czy obie części. Dotyczy to atrybutów typu Pole wyboru, wybór odpowiedzi oraz drzewo wyboru.

Jak widać w kreatorze, sam tag {49} dla pola „wartość” wyświetli ID i nazwę. Jeżeli będziemy chcieli np. wyświetlić tą wartość w innym miejscu, to przy wyborze tagu w takiej formie, wyświetlone zostanie „2#Wartość 2”. Użytkowników raczej nie będzie interesowało ID wybranej wartości, więc można użyć tagu, który wyświetli tylko drugą część wartości – Nazwa {N:49}.
Przedrostki I: oraz N: można łatwo zapamiętać gdyż są to pierwsze litery odpowiednio ID oraz Name.
Dla pokazania tego na przykładzie, możemy wykorzystać przedstawiony powyżej atrybut Wartość.
Ma on 3 możliwe do wybrania wartości – Wartość 1 (ID 1), Wartość 2 (ID 2), Wartość 3 (ID3). Na pierwszym kroku obiegu wybieramy jedną z opcji i przechodzimy do drugiego kroku, gdzie wyświetlane będą trzy nowe pola tekstowe:
- Wartość ID – pole, które jako wartość domyślną przyjmuje ID pola Wartość
- Wartość Nazwa – pole, które jako wartość domyślną przyjmują Nazwę pola Wartość.
- Wartość ID i nazwa – pole, które wyświetli ID i nazwę pola Wartość.
Powinniśmy dostać taki efekt:

Zastosowań tej funkcjonalności jest wiele i są często stosowane w praktyce.
Tworząc np. warunki ograniczające widoczność atrybutów, warunki wykonania akcji czy same akcje walidacji, zdecydowanie lepiej jest wykonywać porównanie na podstawie ID pickera niż na podstawie jego wartości (nazwy).
Nazwa może w przyszłości ulec zmianie, ID zawsze pozostanie dla danej wartości takie samo. Innym wartym odnotowania przykładem może być obieg dostępny dla kilku spółek z różnych krajów, wykorzystujący tłumaczenia i słowniki z tymi samymi wartościami, ale w różnych językach. Jedno pole wyboru, może więc w zależności od spółki korzystać z różnych słowników, zawierających te same wartości, ale w innych językach.
Z kolei, jeżeli wybraną w pickerze wartość (nazwę), będziemy chcieli wyświetlić w innym miejscu to lepszym wyborem jest wyświetlenie samej nazwy, gdyż poza szczególnymi przypadkami, ID wybranej wartości nie powinno mieć znaczenia dla użytkownika.
W przypadku pól typu „Data i godzina” mamy bardzo duże możliwości wyboru formatowania wyświetlanej daty.
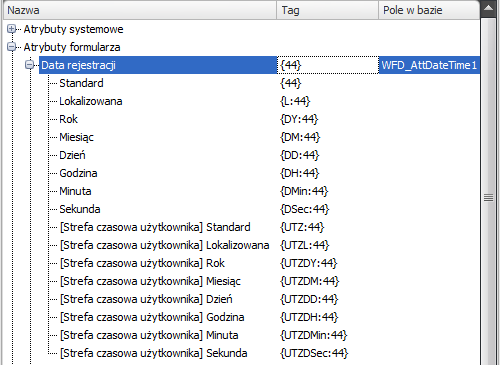
Wyświetlanie poszczególnych części składowych daty ze wskazanego atrybutu może znacznie przyśpieszyć tworzenie zapytania – nie musimy przypominać sobie lub szukać odpowiednich funkcji SQL, które wyciągną np. numer miesiąca z podanej daty. Wystarczy użyć odpowiedniego tagu.
Wyjaśnienia może wymagać tutaj Tag {L:44}, który wyświetla wartość lokalizowaną. Jej wartość jest ustawiana w zależności od ustawionego języka przeglądarki.
Warto tutaj nadmienić, że przedrostek L: może też być stosowany w tagach odpowiadającym atrybutom typu ”Tak/Nie”. Wtedy zamiast wyświetlać True/False, wybór wyświetlany będzie w języku, jaki jest ustawiony w przeglądarce.
W przypadku pól typu „Liczba zmiennoprzecinkowa” mamy możliwość wymuszenia formatowania znaku rozdzielającego część całkowitą i dziesiętną. W zależności od języka przeglądarki może być stosowany różny standard – np. dla Amerykańskiej odmiany języka Angielskiego, stosowana będzie domyślnie kropka, a dla języka Polskiego standardem jest stosowanie przecinka.
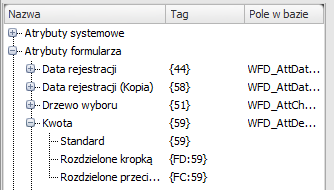
W sytuacji gdy chcemy umożliwić wydruk PDF dokumentu w WorkFlow a z uwagi na różny język u użytkowników, nie chcemy żeby na części wydruków widniały kwoty rozdzielone kropką a na części przecinkiem, możemy wymusić wyświetlanie jednego standardu.
Następnym rodzajem atrybutów, dla których mamy możliwość formatowania wyświetlanych danych jest typ „Osoba lub grupa”. Mamy tutaj możliwość wyświetlenia podstawowych informacji (nazwa, login, email) na temat osoby, która została wskazana w danym polu oraz także podstawowe informacje o jej przełożonym, wyznaczanym na podstawie struktury podległościowej.
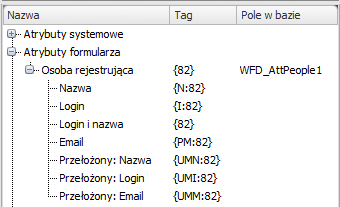
W praktyce wygląda to w ten sposób:

Ważną informacją jest to, że w grupie tagów „Atrybuty formularza” nie będą widoczne listy pozycji. Jest to związane z tym, że lista może zawierać wiele wierszy, więc nie ma jednej konkretnej wartości kolumny, do której można się bezpośrednio odnieść. Pobranie wartości atrybutów z listy pozycji jest nieco bardziej skomplikowane niż z pojedynczego atrybutu, ale nie znaczy to, że stworzenie takiego zapytania jest trudne.
Pomocne przy konstrukcji zapytania jest grupa „Identyfikator obiektów”. Tagi spod tej grupy, zamieniane są ID/Nazwę (w zależności od użytkownika) wskazujące na konkretny obiekt w procesie. Może to być sam proces, atrybut, typ dokumentu, obieg, krok albo ścieżka przejścia.
Wyobraźmy sobie sytuację, że mamy listę pozycji z jedną kolumną – pojedynczy wiersz tekstu o nazwie „Wartość”. Chcemy wymusić na zakończenie kroku, aby w jednym z wierszy znajdowała się wartość „Bazinga!”. W tym celu tworzymy akcję walidacji SQL na zakończenie kroku.
Akcję konfigurujemy w następujący sposób
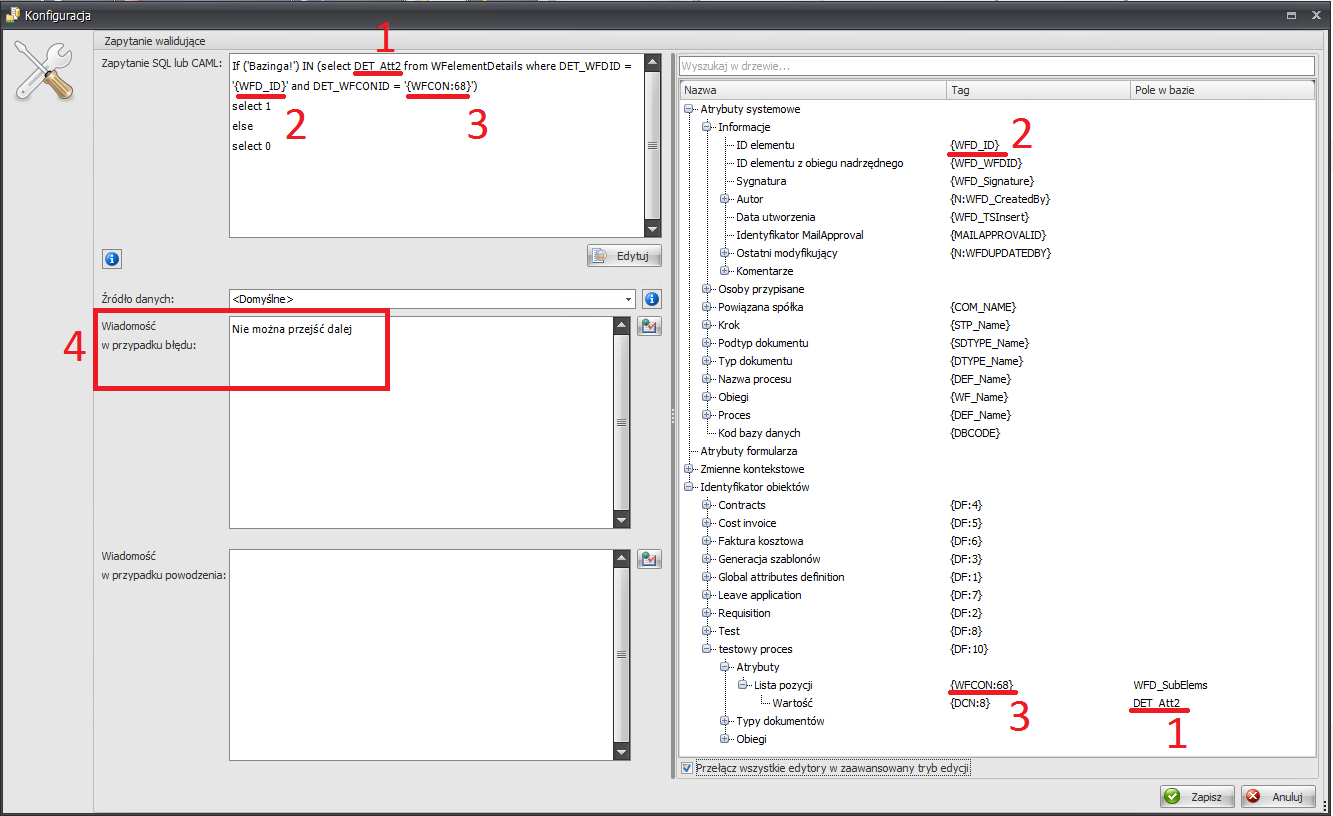
W celu pobrania wszystkich wierszy „Wartość” dla naszej listy musimy poznać nazwę tego pola w bazie danych. W tym celu rozwijamy „Identyfikator obiektów”, wyszukujemy nasz proces a następnie utworzoną listę pozycji. W trybie zaawansowanym wyświetli nam się poszukiwana nazwa pola – DET_Att2 (nr 1 na screenshot’cie).
Tabela WfElementDetails zawiera wszystkie utworzone wiersze dla list pozycji utworzonych.
Kolumna DET_WFDID zawiera ID dokumentu, którego dana lista pozycji dotyczy, więc można ją użyć do zawężenia wszystkich rekordów do tylko tych, które dotyczą obecnie przeglądanego dokumentu (nr 2 na screenshot’cie). Na tym można by zakończyć zawężenie, ale dobrym nawykiem jest dodatkowo zawsze zawężać rezultat zapytania do konkretnej listy pozycji, nawet jeżeli na obiegu obecnie utworzona jest tylko jedna lista.
W tym przykładzie istnieje tylko jedna lista pozycji, więc dla dokumentu o ID 22, znajdzie tylko wiersze dla listy „Lista pozycji”.
Jeżeli jednak w przyszłości zdecydujemy się na dodanie drugiej listy pozycji do obiegu, to wtedy będą dwie listy dla tego dokumentu, które będą mogły mieć pola DET_Att2 i zapytanie będzie sprawdzało wartości tego pola także dla drugiej listy pozycji. Dlatego warto zawczasu zabezpieczyć się przed taką sytuacją zawsze dodatkowo zawężając otrzymane wyniki do konkretnej listy pozycji.
Tag naszej listy pozycji, który zostanie zamieniony na jej ID, możemy także znaleźć w menu „Identyfikator obiektów” – nr 3 na screenshot’cie.
Na koniec zdefiniujmy wiadomość w przypadku błędu, która jest wyświetlana, jeżeli zapytanie SQL zwróci 0 czyli nie znajdzie wiersza z wartością „Bazinga!”.
Przetestujmy teraz nasze rozwiązanie:
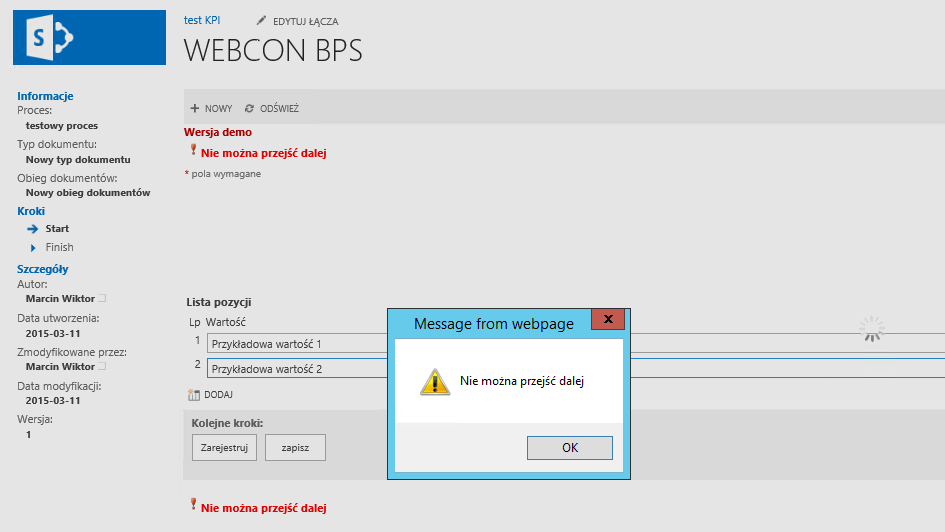
Zgodnie z założeniem, nie możemy przejść dalej. Jednakże, po dodaniu wiersza z wartością „Bazinga!” system powinien nas już bez problemu przepuścić.
Innym, bardzo często wykorzystywanym w praktyce przykładem zastosowania tagów z grupy „Identyfikator obiektów” może być sprawdzanie typu dokumentu.
W sytuacji gdy mamy 2 typy dokumentów i chcemy wymusić, aby każdy z nich przechodził inną ścieżką (np. w celu ułatwienia walidacji, przypisywania zadań czy pomijania kroku pośredniego). Nie chcemy dopuścić do sytuacji, gdy użytkownik się pomyli, przechodząc przypadkowo ścieżką przeznaczoną dla drugiego typu dokumentów.
Do tego celu wykorzystamy tag z grupy atrybutów systemowych wskazującego na ID typu dokumentu, dla naszego dokumentu i tagu z grupy Identyfikatorów obiektów, który wskazuje jeden z utworzonych w procesie typów dokumentu.
Przygotowujemy proste zapytanie, które należy wkleić w ustawieniach ścieżki, w sekcji „Ogranicz widoczność (SQL)”:

O tym, jaka jest przewaga porównywania ID elementów nad porównywaniem ich nazw można przeczytać więcej w rozdziale 4 „Dobre praktyki”.
3. Pozostałe grupy tagów
Grupa tagów „Atrybuty systemowe” zawiera elementy związane z danym dokumentem, dla którego interpretowane jest wyrażenie. Można tutaj znaleźć tagi odpowiadające takim informacjom jak:
- Id dokumentu, ID dokumentu nadrzędnego w stosunku do obecnego (jeżeli istnieje)
- Autor (nazwa, login, email, login bez domeny)
- Sygnatura dokumentu
- Osoby przypisane do dokumentu (bezpośrednio lub do wiadomości)
- Spółka powiązana z dokumentem (dostępne są wszystkie atrybuty opisujące daną spółkę, zdefiniowane w jej konfiguracji)
- Obecny krok, w którym znajduje się dokument (ID, nazwa, opis)
- Typ oraz podtyp dokumentu (jeżeli istnieje)
Oraz kilka innych elementów.
Drugą grupą, dostępna prawie zawsze w kreatorze wyrażeń są „Zmienne kontekstowe”. Zawiera ona elementy takie jak Aktualnie zalogowany użytkownik, bieżąca data, punkt rejestracji z poziomu którego modyfikowany jest dokument czy informacje o ścieżkach przejścia (ścieżka domyślna dla kroku oraz ścieżką, która została wybrana w trakcie przejścia dokumentu).
Trzecią grupą tagów, z którą możemy się spotkać w BPS jest grupa „Sygnatura”. Jest ona dostępna tylko w miejscach gdzie definiujemy sygnaturę dla typu dokumentów lub dla obiegu. Znajdują się tutaj elementy, które możemy wstawić do definicji sygnatury, takie jak:
- Aktualny dzień, miesiąc oraz rok
- Punkt rejestracji, w którym utworzono dokument
- Numeracja ciągła (z możliwością ustawienia autouzupełniania numeru do 10 znaków)
- Numeracja w roku, miesiącu lub dniu bieżącym
- Numeracja w obrębie wartości z danego atrybutu (tylko dla atrybutów typu „Data i godzina”)
Dodatkowo po rozwinięciu drzewa numeracji w danym okresie, możemy wybrać opcję numeracji nie tylko w obrębie danej jednostki czasu, ale w obrębie dnia/miesiąca/roku i spółki.
Warto nadmienić fakt, iż pomimo w kreatorze wyrażeń można wybrać autouzupełnianie tylko do 10 znaków, to modyfikując ręcznie liczbę w tagu numeracji, można zwiększyć autouzupełnianie aż do 20 znaków.
Ostatnią grupą tagów, która podobnie jak grupa „Sygnatura”, jest dostępna tylko w kilku miejscach w BPS jest grupa „Szablon email”. Grupa ta jest widoczna tylko w miejscach, w którym edytujemy szablony email. Znajdują się tam podstawowe elementy szablonu takie jak np. Adres elementu, adres witryny, lista atrybutów czy treść wiadomości.
Istnieją jeszcze pojedyncze tagi, niewidoczne z poziomu kreatora wyrażeń, ale możliwe do wykorzystania po ich ręcznym wpisaniu. Przykładami takich tagów są:
- {AD:parametr} – wartość podanego w nazwie parametru w profilu AD dla zalogowanego użytkownika. Parametry z Active Directory są obsługiwane wszędzie tam gdzie tagi. Wielkość znaków w nazwie parametru nie ma znaczenia.
- {R:nazwa} – wartość parametru podanego w Requeście. Wartości z Requestu nie są obsługiwane w akcjach (wyjątkiem jest akcja Odsyłacz) oraz nie są obsługiwane w generacji dokumentów i wydruków (HTML, PDF, docx)
- {WSS:parametr} – wartość podanego w nazwie parametru w profilu WSS dla zalogowanego użytkownika. Parametry z WSS są obsługiwane wszędzie tam gdzie tagi. Wielkość znaków w nazwie parametru nie ma znaczenia.
Listę wszystkich dostępnych tagów jest zawsze dostępna w pomocy do BPS Studio (klawisz F1) pod tematem „Zmienne”.
4. Dobre praktyki
Dlaczego warto stosować tagi tam gdzie tylko jest to możliwe? Największą zaletą zdecydowanie jest automatyczna podmiana tagów przy klonowaniu procesu albo przenoszeniu go między środowiskami. Wyobraźmy sobie sytuację, że jako warunek wykonania pewnej akcji mamy prosty warunek IF:
If (‘{DTYPE_ID}’ = 54) select 1 else select 0
Dla naszego procesu wprawdzie akcja będzie się zawsze poprawnie wykonywała, ale jeżeli kiedyś postanowimy przenieść ten proces na inny serwer (np. z serwera testowego na produkcyjny) to istnieje duże prawdopodobieństwo, że po imporcie procesu, ID tego typu dokumentów będzie inny niż 54.
Jeżeli powyższe zapytanie zmodyfikujemy w ten sposób:
if ('{DTYPE_ID}' = '{DT:54}') select 1 else select 0
Wówczas podczas importu procesu, BPS automatycznie zamieni ID tego typu dokumentów w tagach na nowe ID, które zostało im przypisane.
Dla przykładu – jeżeli po migracji procesu, ID tego typu dokumentów zmieni się z 54 na 75 to powyższe zapytanie podczas importu zostanie automatycznie podmieniona na:
if ('{DTYPE_ID}' = '{DT:75}') select 1 else select 0
Drugą zaletą stosowania takich jest znacznie większa przejrzystość procesu w BPS studio, co widać nawet na powyższym przykładzie. Po zobaczeniu pierwszego warunku, musielibyśmy ręcznie poszukać, który typ dokumentów ma ID 54 żeby zrozumieć, kiedy akcja powinna się wykonywać. Jeżeli skorzystamy z drugiego warunku, to tag {DT:54} zostanie automatycznie zamieniony na nazwę wskazanego typu dokumentów.
Na koniec warto dodać coś, co powinno być oczywiste po zaznajomieniu się z tym artykułem – wykorzystanie tagów po prostu znacznie ułatwia i przyśpiesza pracę.